Try sign translate to experience state-of-the art-sign language translation technology.
Introduction
Signed languages (also known as sign languages) are languages that use the visual-gestural modality to convey meaning through manual articulations in combination with non-manual elements like the face and body. They serve as the primary means of communication for numerous deaf and hard-of-hearing individuals. Similar to spoken languages, signed languages are natural languages governed by a set of linguistic rules (Sandler and Lillo-Martin 2006), both emerging through an abstract, protracted aging process and evolving without deliberate meticulous planning. Signed languages are not universal or mutually intelligible, despite often having striking similarities among them. They are also distinct from spoken languages—i.e., American Sign Language (ASL) is not a visual form of English but its own unique language.
Sign Language Processing (Bragg et al. 2019; Yin et al. 2021) is an emerging field of artificial intelligence concerned with the automatic processing and analysis of sign language content. While research has focused more on the visual aspects of signed languages, it is a subfield of both Natural Language Processing (NLP) and Computer Vision (CV). Challenges in sign language processing often include machine translation of sign language videos into spoken language text (sign language translation), from spoken language text (sign language production), or sign language recognition for sign language understanding.
Unfortunately, the latest advances in language-based artificial intelligence, like machine translation and personal assistants, expect a spoken language input (text or transcribed speech), excluding around 200 to 300 different signed languages (United Nations 2022) and up to 70 million deaf people (World Health Organization 2021; World Federation of the Deaf 2022).
Throughout history, Deaf communities fought for the right to learn and use signed languages and for the public recognition of signed languages as legitimate ones. Indeed, signed languages are sophisticated communication modalities, at least as capable as spoken languages in all aspects, both linguistic and social. However, in a predominantly oral society, deaf people are constantly encouraged to use spoken languages through lip-reading or text-based communication. The exclusion of signed languages from modern language technologies further suppresses signing in favor of spoken languages. This exclusion disregards the preferences of the Deaf communities who strongly prefer to communicate in signed languages both online and for in-person day-to-day interactions, among themselves and when interacting with spoken language communities (C. A. Padden and Humphries 1988; Glickman and Hall 2018). Thus, it is essential to make signed languages accessible.
To date, a large amount of research on Sign Language Processing (SLP) has been focused on the visual aspect of signed languages, led by the Computer Vision (CV) community, with little NLP involvement. This focus is not unreasonable, given that a decade ago, we lacked adequate CV tools to process videos for further linguistic analyses. However, similar to spoken languages, signed languages are fully-fledged systems exhibiting all the fundamental characteristics of natural languages, and existing SLP techniques do not adequately address or leverage the linguistic structure of signed languages. Signed languages introduce novel challenges for NLP due to their visual-gestural modality, simultaneity, spatial coherence, and lack of written form. The lack of a written form makes the spoken language processing pipelines - which often start with audio transcription before processing - incompatible with signed languages, forcing researchers to work directly on the raw video signal.
Furthermore, SLP is not only intellectually appealing but also an important research area with significant potential to benefit signing communities. Beneficial applications enabled by signed language technologies include improved documentation of endangered sign languages; educational tools for sign language learners; tools for query and retrieval of information from signed language videos; personal assistants that react to signed languages; real-time automatic sign language interpretations; and more. Needless to say, in addressing this research area, researchers should work alongside and under the direction of deaf communities, and to benefit the signing communities’ interest above all (Harris, Holmes, and Mertens 2009).
In this work, we describe the different representations used for sign language processing, as well as survey the various tasks and recent advances on them. We also make a comprehensive list of existing datasets and make the ones available easy to load using a simple and standardized interface.
(Brief) History of Signed Languages and Deaf Culture
Throughout modern history, spoken languages were dominant, so much so that signed languages struggled to be recognized as languages in their own right, and educators developed misconceptions that signed language acquisition might hinder the development of speech skills. For example, in 1880, a large international conference of deaf educators called the “Second International Congress on Education of the Deaf” banned teaching signed languages, favoring speech therapy instead. It was not until the seminal work on American Sign Language (ASL) by Stokoe Jr (1960) that signed languages started gaining recognition as natural, independent, and well-defined languages, which inspired other researchers to further explore signed languages as a research area. Nevertheless, antiquated attitudes that placed less importance on signed languages continue to inflict harm and subject many to linguistic neglect (Humphries et al. 2016). Several studies have shown that deaf children raised solely with spoken languages do not gain enough access to a first language during their critical period of language acquisition (Murray, Hall, and Snoddon 2020). This language deprivation can lead to life-long consequences on the cognitive, linguistic, socio-emotional, and academic development of the deaf (Hall, Levin, and Anderson 2017).
Signed languages are the primary languages of communication for the Deaf1 and are at the heart of Deaf communities. In the past, the failure to recognize signed languages as fully-fledged natural language systems in their own right has had detrimental effects, and in an increasingly digitized world, NLP research should strive to enable a world in which all people, including the Deaf, have access to languages that fit their lived experience.
Sign Language Linguistics Overview
Signed languages consist of phonological, morphological, syntactic, and semantic levels of structure that fulfill the same social, cognitive, and communicative purposes as other natural languages. While spoken languages primarily channel the oral-auditory modality, signed languages use the visual-gestural modality, relying on the signer’s face, hands, body, and space around them to create distinctions in meaning. We present the linguistic features of signed languages2 that researchers must consider during their modeling.
Phonology
Signs are composed of minimal units that combine manual features such as hand configuration, palm orientation, placement, contact, path movement, local movement, as well as non-manual features including eye aperture, head movement, and torso positioning (Liddell and Johnson 1989; Johnson and Liddell 2011; Brentari 2011; Sandler 2012). Not all possible phonemes are realized in both signed and spoken languages, and inventories of two languages’ phonemes/features may not overlap completely. Different languages are also subject to rules for the allowed combinations of features.
Simultaneity
Though an ASL sign takes about twice as long to produce than an English word, the rates of transmission of information between the two languages are similar (Bellugi and Fischer 1972). One way signed languages compensate for the slower production rate of signs is through simultaneity: Signed languages use multiple visual cues to convey different information simultaneously (Sandler 2012). For example, the signer may produce the sign for “cup” on one hand while simultaneously pointing to the actual cup with the other to express “that cup.” Similarly to tone in spoken languages, the face and torso can convey additional affective information (Liddell and others 2003; Johnston and Schembri 2007). Facial expressions can modify adjectives, adverbs, and verbs; a head shake can negate a phrase or sentence; eye direction can help indicate referents.
Referencing
The signer can introduce referents in discourse either by pointing to their actual locations in space or by assigning a region in the signing space to a non-present referent and by pointing to this region to refer to it (Rathmann and Mathur 2011; Schembri, Cormier, and Fenlon 2018). Signers can also establish relations between referents grounded in signing space by using directional signs or embodying the referents using body shift or eye gaze (Dudis 2004; Liddell and Metzger 1998). Spatial referencing also impact morphology when the directionality of a verb depends on the location of the reference to its subject and/or object (Beuzeville 2008; Fenlon, Schembri, and Cormier 2018): For example, a directional verb can move from its subject’s location and end at its object’s location. While the relation between referents and verbs in spoken language is more arbitrary, referent relations are usually grounded in signed languages. The visual space is heavily exploited to make referencing clear.
Another way anaphoric entities are referenced in sign language is by using classifiers or depicting signs (Supalla 1986; Wilcox and Hafer 2004; Roy 2011) that help describe the characteristics of the referent. Classifiers are typically one-handed signs that do not have a particular location or movement assigned to them, or derive features from meaningful discourse (Liddell and others 2003), so they can be used to convey how the referent relates to other entities, describe its movement, and give more details. For example, to tell about a car swerving and crashing, one might use the hand classifier for a vehicle, move it to indicate swerving, and crash it with another entity in space.
To quote someone other than oneself, signers perform role shift (Cormier, Smith, and Sevcikova-Sehyr 2015), where they may physically shift in space to mark the distinction and take on some characteristics of the people they represent. For example, to recount a dialogue between a taller and a shorter person, the signer may shift to one side and look up when taking the shorter person’s role, shift to the other side and look down when taking the taller person’s role.
Fingerspelling
Fingerspelling results from language contact between a signed language and a surrounding spoken language written form (Battison 1978; Wilcox 1992; Brentari and Padden 2001; Patrie and Johnson 2011). A set of manual gestures correspond with a written orthography or phonetic system. This phenomenon, found in most signed languages, is often used to indicate names or places or new concepts from the spoken language but has often become integrated into the signed languages as another linguistic strategy (Padden 1998; Montemurro and Brentari 2018).
Sign Language Representations
Representation is a significant challenge for SLP. Unlike spoken languages, signed languages have no widely adopted written form. As signed languages are conveyed through the visual-gestural modality, video recording is the most straightforward way to capture them. However, as videos include more information than needed for modeling and are expensive to record, store, and transmit, a lower-dimensional representation has been sought after.
The following figure illustrates each signed language representation we will describe below. In this demonstration, we deconstruct the video into its individual frames to exemplify the alignment of the annotations between the video and representations.
Videos
are the most straightforward representation of a signed language and can amply incorporate the information conveyed through signing. One major drawback of using videos is their high dimensionality: They usually include more information than needed for modeling and are expensive to store, transmit, and encode. As facial features are essential in sign, anonymizing raw videos remains an open problem, limiting the possibility of making these videos publicly available (Isard 2020).
Skeletal Poses
reduce the visual cues in videos to skeleton-like wireframes or mesh representing the location of joints. This technique has been extensively used in the field of computer vision to estimate human pose from video data, where the goal is to determine the spatial configuration of the body at each point in time. Although high-quality pose estimation can be achieved using motion capture equipment, such methods are often expensive and intrusive. As a result, estimating pose from videos has become the preferred method in recent years (Pishchulin et al. 2012; Chen et al. 2017; Cao et al. 2019; Güler, Neverova, and Kokkinos 2018). Compared to video representations, accurate skeletal poses have a lower complexity and provide a semi-anonymized representation of the human body, while observing relatively low information loss. However, they remain a continuous, multidimensional representation that is not adapted to most NLP models.
Written notation systems
represent signs as discrete visual features. Some systems are written linearly, and others use graphemes in two dimensions. While various universal (Sutton 1990; Prillwitz and Zienert 1990) and language-specific notation systems (Stokoe Jr 1960; Kakumasu 1968; Bergman 1977) have been proposed, no writing system has been adopted widely by any sign language community, and the lack of standards hinders the exchange and unification of resources and applications between projects. The figure above depicts two universal notation systems: SignWriting (Sutton 1990), a two-dimensional pictographic system, and HamNoSys (Prillwitz and Zienert 1990), a linear stream of graphemes designed to be machine-readable.
Glosses
are the transcription of signed languages sign-by-sign, with each sign having a unique semantic identifier. While various sign language corpus projects have provided guidelines for gloss annotation (Mesch and Wallin 2015; Johnston and De Beuzeville 2016; Konrad et al. 2018), a standardized gloss annotation protocol has yet to be established. Linear gloss annotations have been criticized for their imprecise representation of signed language. These annotations fail to capture all the information expressed simultaneously through different cues, such as body posture, eye gaze, or spatial relations, leading to a loss of information that can significantly affect downstream performance on SLP tasks (Yin and Read 2020; Müller et al. 2023).
Müller et al. (2023) conduct an extensive review of the use of glosses in sign language translation research and make the following recommendations for research using glosses:
- Demonstrate awareness of limitations of gloss approaches and explicitly discuss them.
- Focus on datasets beyond RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018). Openly discuss the limited size and linguistic domain of this dataset.
- Use metrics that are well-established in MT. If BLEU (Papineni et al. 2002) is used, compute it with SacreBLEU (Post 2018), report metric signatures and disable internal tokenization for gloss outputs. Do not compare to scores produced with a different or unknown evaluation procedure.
- Given that glossing is corpus-specific, process glosses in a corpus-specific way, informed by transcription conventions.
- Optimize gloss translation baselines with methods shown to be effective for low-resource MT.
The following table additionally exemplifies the various representations for more isolated signs. For this example, we use SignWriting as the notation system. Note that the same sign might have two unrelated glosses, and the same gloss might have multiple valid spoken language translations.
| Video | Pose Estimation | Notation | Gloss | English Translation |
|---|---|---|---|---|
 |
 |
 |
HOUSE | House |
 |
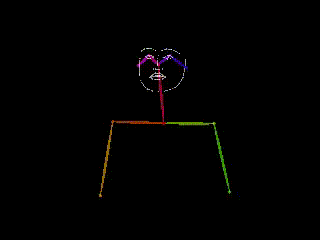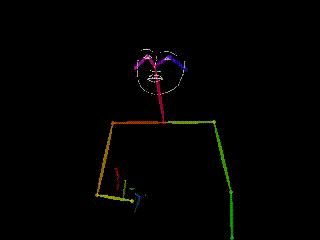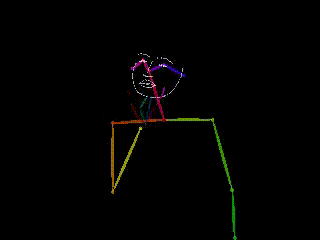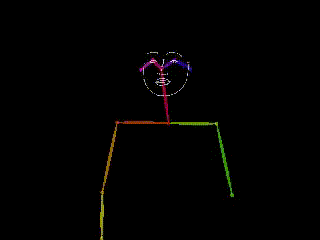 |
 |
WRONG-WHAT | What’s the matter? What’s wrong? |
 |
 |
 |
DIFFERENT BUT |
Different But |
Tasks
So far, the computer vision community has primarily led the SLP research to focus on processing the visual features in signed language videos. As a result, current SLP methods do not fully address the linguistic complexity of signed languages. We survey common SLP tasks and current methods’ limitations, drawing on signed languages’ linguistic theories.
Sign Language Detection
Sign language detection (Borg and Camilleri 2019; Moryossef et al. 2020; Pal et al. 2023) is the binary classification task of determining whether signing activity is present in a given video frame. A similar task in spoken languages is voice activity detection (VAD) (Sohn, Kim, and Sung 1999; Ramırez et al. 2004), the detection of when a human voice is used in an audio signal. As VAD methods often rely on speech-specific representations such as spectrograms, they are not necessarily applicable to videos.
Borg and Camilleri (2019) introduced the classification of frames taken from YouTube videos as either signing or not signing. They took a spatial and temporal approach based on VGG-16 (Simonyan and Zisserman 2015) CNN to encode each frame and used a Gated Recurrent Unit (GRU) (Cho et al. 2014) to encode the sequence of frames in a window of 20 frames at 5fps. In addition to the raw frame, they either encoded optical-flow history, aggregated motion history, or frame difference.
Moryossef et al. (2020) improved upon their method by performing sign language detection in real time. They identified that sign language use involves movement of the body and, as such, designed a model that works on top of estimated human poses rather than directly on the video signal. They calculated the optical flow norm of every joint detected on the body and applied a shallow yet effective contextualized model to predict for every frame whether the person is signing or not.
While these recent detection models achieve high performance, we need well-annotated data that include interference and distractions with non-signing instances for proper real-world evaluation. Pal et al. (2023) conducted a detailed analysis of the impact of signer overlap between the training and test sets on two sign detection benchmark datasets (Signing in the Wild (Borg and Camilleri 2019) and the DGS Corpus (Hanke et al. 2020)) used by Borg and Camilleri (2019) and Moryossef et al. (2020). By comparing the accuracy with and without overlap, they noticed a relative decrease in performance for signers not present during training. As a result, they suggested new dataset partitions that eliminate overlap between train and test sets and facilitate a more accurate evaluation of performance.
Sign Language Identification
Sign language identification (Gebre, Wittenburg, and Heskes 2013; Monteiro et al. 2016) classifies which signed language is used in a given video.
Gebre, Wittenburg, and Heskes (2013) found that a simple random-forest classifier utilizing the distribution of phonemes can distinguish between British Sign Language (BSL) and Greek Sign Language (ENN) with a 95% F1 score. This finding is further supported by Monteiro et al. (2016), which, based on activity maps in signing space, manages to differentiate between British Sign Language and French Sign Language (Langue des Signes Française, LSF) with a 98% F1 score in videos with static backgrounds, and between American Sign Language and British Sign Language, with a 70% F1 score for videos mined from popular video-sharing sites. The authors attribute their success mainly to the different fingerspelling systems, which are two-handed in the case of BSL and one-handed in the case of ASL and LSF.
Although these pairwise classification results seem promising, better models would be needed for classifying from a large set of signed languages. These methods only rely on low-level visual features, while signed languages have several distinctive features on a linguistic level, such as lexical or structural differences (McKee and Kennedy 2000; Kimmelman 2014; Ferreira-Brito 1984; Shroyer and Shroyer 1984) which have not been explored for this task.
Sign Language Segmentation
Segmentation consists of detecting the frame boundaries for signs or phrases in videos to divide them into meaningful units. While the most canonical way of dividing a spoken language text is into a linear sequence of words, due to the simultaneity of sign language, the notion of a sign language “word” is ill-defined, and sign language cannot be fully linearly modeled.
Current methods resort to segmenting units loosely mapped to signed language units (Santemiz et al. 2009; Farag and Brock 2019; Bull, Gouiffès, and Braffort 2020; Renz, Stache, et al. 2021a, 2021b; Bull et al. 2021) and do not explicitly leverage reliable linguistic predictors of sentence boundaries such as prosody in signed languages (i.e., pauses, extended sign duration, facial expressions) (Sandler 2010; Ormel and Crasborn 2012). De Sisto et al. (2021) call for a better understanding of sign language structure, which they believe is the necessary ground for the design and development of sign language recognition and segmentation methodologies.
Santemiz et al. (2009) automatically extracted isolated signs from continuous signing by aligning the sequences obtained via speech recognition, modeled by Dynamic Time Warping (DTW) and Hidden Markov Models (HMMs) approaches.
Farag and Brock (2019) used a random forest classifier to distinguish frames containing signs in Japanese Sign Language based on the composition of spatio-temporal angular and distance features between domain-specific pairs of joint segments.
Bull, Gouiffès, and Braffort (2020) segmented French Sign Language into segments corresponding to subtitle units by relying on the alignment between subtitles and sign language videos, leveraging a spatio-temporal graph convolutional network (ST-GCN; Yu, Yin, and Zhu (2018)) with a BiLSTM on 2D skeleton data.
Renz, Stache, et al. (2021a) located temporal boundaries between signs in continuous sign language videos by employing 3D convolutional neural network representations with iterative temporal segment refinement to resolve ambiguities between sign boundary cues. Renz, Stache, et al. (2021b) further proposed the Changepoint-Modulated Pseudo-Labelling (CMPL) algorithm to solve the problem of source-free domain adaptation.
Bull et al. (2021) presented a Transformer-based approach to segment sign language videos and align them with subtitles simultaneously, encoding subtitles by BERT (Devlin et al. 2019) and videos by CNN video representations.
Moryossef, Jiang, et al. (2023) presented a method motivated by linguistic cues observed in sign language corpora, such as prosody (pauses, pace, etc) and handshape changes. They also find that using BIO, an annotation scheme that notes the beginning, inside and outside, makes a significant difference over previous ones that only note IO (inside or outside). They find that including optical flow and 3D hand normalization helps with out-of-domain generalization and other signed languages as well.
Sign Language Recognition, Translation, and Production
Sign language translation (SLT) commonly refers to the translation of signed language to spoken language (De Coster et al. 2022; Müller et al. 2022). Sign language production is the reverse process of producing a sign language video from spoken language text. Sign language recognition (SLR) (Adaloglou et al. 2020) detects and labels signs from a video, either on isolated (Imashev et al. 2020; Sincan and Keles 2020) or continuous (Cui, Liu, and Zhang 2017; Camgöz et al. 2018; N. C. Camgöz et al. 2020b) signs.
In the following graph, we can see a fully connected pentagon where each node is a single data representation, and each directed edge represents the task of converting one data representation to another.
We split the graph into two:
- Every edge to the left, on the orange background, represents a task in computer vision. These tasks are inherently language-agnostic; thus, they generalize between signed languages.
- Every edge to the right, on the blue background, represents a task in natural language processing. These tasks are sign language-specific, requiring a specific sign language lexicon or spoken language tokens.
- Every edge on both backgrounds represents a task requiring a combination of computer vision and natural language processing.

There are 20 tasks conceptually defined by this graph, with varying amounts of previous research. Every path between two nodes might or might not be valid, depending on how lossy the tasks in the path are.
Video-to-Pose
Video-to-Pose—commonly known as pose estimation—is the task of detecting human figures in images and videos, so that one could determine, for example, where someone’s elbow shows up in an image. It was shown that the face pose correlates with facial non-manual features like head direction (Vogler and Goldenstein 2005).
This area has been thoroughly researched (Pishchulin et al. 2012; Chen et al. 2017; Cao et al. 2019; Güler, Neverova, and Kokkinos 2018) with objectives varying from predicting 2D / 3D poses to a selection of a small specific set of landmarks or a dense mesh of a person.
OpenPose (Cao et al. 2019; Simon et al. 2017; Cao et al. 2017; Wei et al. 2016) is the first multi-person system to jointly detect human body, hand, facial, and foot keypoints (in total 135 keypoints) in 2D on single images. While their model can estimate the full pose directly from an image in a single inference, they also suggest a pipeline approach where they first estimate the body pose and then independently estimate the hands and face pose by acquiring higher resolution crops around those areas. Building on the slow pipeline approach, a single network whole body OpenPose model has been proposed (Martinez et al. 2019), which is faster and more accurate for the case of obtaining all keypoints. With multiple recording angles, OpenPose also offers keypoint triangulation to reconstruct the pose in 3D.
DensePose (Güler, Neverova, and Kokkinos 2018) takes a different approach. Instead of classifying for every keypoint which pixel is most likely, they suggest a method similar to semantic segmentation, for each pixel to classify which body part it belongs to. Then, for each pixel, knowing the body part, they predict where that pixel is on the body part relative to a 2D projection of a representative body model. This approach results in the reconstruction of the full-body mesh and allows sampling to find specific keypoints similar to OpenPose.
However, 2D human poses might not be sufficient to fully understand the position and orientation of landmarks in space, and applying pose estimation per frame disregards video temporal movement information into account, especially in cases of rapid movement, which contain motion blur.
Pavllo et al. (2019) developed two methods to convert between 2D poses to 3D poses. The first, a supervised method, was trained to use the temporal information between frames to predict the missing Z-axis. The second is an unsupervised method, leveraging the fact that the 2D poses are merely a projection of an unknown 3D pose and training a model to estimate the 3D pose and back-project to the input 2D poses. This back projection is a deterministic process, applying constraints on the 3D pose encoder. Zelinka and Kanis (2020) followed a similar process and added a constraint for bones to stay of a fixed length between frames.
Panteleris, Oikonomidis, and Argyros (2018) suggest converting the 2D poses to 3D using inverse kinematics (IK), a process taken from computer animation and robotics to calculate the variable joint parameters needed to place the end of a kinematic chain, such as a robot manipulator or animation character’s skeleton, in a given position and orientation relative to the start of the chain. Demonstrating their approach to hand pose estimation, they manually explicitly encode the constraints and limits of each joint, resulting in 26 degrees of freedom. Then, non-linear least-squares minimization fits a 3D model of the hand to the estimated 2D joint positions, recovering the 3D hand pose. This process is similar to the back-projection used by Pavllo et al. (2019), except here, no temporal information is being used.
MediaPipe Holistic (Grishchenko and Bazarevsky 2020) attempts to solve 3D pose estimation by taking a similar approach to OpenPose, having a pipeline system to estimate the body, then the face and hands. Unlike OpenPose, the estimated poses are in 3D, and the pose estimator runs in real-time on CPU, allowing for pose-based sign language models on low-powered mobile devices. This pose estimation tool is widely available and built for Android, iOS, C++, Python, and the Web using JavaScript.
Pose-to-Video
Pose-to-Video, also known as motion transfer or skeletal animation in the field of robotics and animation, is the conversion of a sequence of poses to a video. This task is the final “rendering” of sign language in a visual modality.
Chan et al. (2019) demonstrated a semi-supervised approach where they took a set of videos, ran pose estimation with OpenPose (Cao et al. 2019), and learned an image-to-image translation (Isola et al. 2017) between the rendered skeleton and the original video. They demonstrated their approach on human dancing, extracting poses from a choreography and rendering any person as if they were dancing. They predicted two consecutive frames for temporally coherent video results and introduced a separate pipeline for a more realistic face synthesis, although still flawed.
Wang et al. (2018) suggested a similar method using DensePose (Güler, Neverova, and Kokkinos 2018) representations in addition to the OpenPose (Cao et al. 2019) ones. They formalized a different model, with various objectives to optimize for, such as background-foreground separation and temporal coherence by using the previous two timestamps in the input.
Using the method of Chan et al. (2019) on “Everybody Dance Now”, Giró-i-Nieto (2020) asked, “Can Everybody Sign Now?” and investigated if people could understand sign language from automatically generated videos. They conducted a study in which participants watched three types of videos: the original signing videos, videos showing only poses (skeletons), and reconstructed videos with realistic signing. The researchers evaluated the participants’ understanding after watching each type of video. Results revealed a preference for reconstructed videos over skeleton videos. However, the standard video synthesis methods used in the study were not effective enough for clear sign language translation. Participants had trouble understanding the reconstructed videos, suggesting that improvements are needed for better sign language translation in the future.
As a direct response, Saunders, Camgöz, and Bowden (2020a) showed that like in Chan et al. (2019), where an adversarial loss was added to specifically generate the face, adding a similar loss to the hand generation process yielded high-resolution, more photo-realistic continuous sign language videos. To further improve the hand image synthesis quality, they introduced a keypoint-based loss function to avoid issues caused by motion blur.
In a follow-up paper, Saunders, Camgöz, and Bowden (2021) introduced the task of Sign Language Video Anonymisation (SLVA) as an automatic method to anonymize the visual appearance of a sign language video while retaining the original sign language content. Using a conditional variational autoencoder framework, they first extracted pose information from the source video to remove the original signer appearance, then generated a photo-realistic sign language video of a novel appearance from the pose sequence. The authors proposed a novel style loss that ensures style consistency in the anonymized sign language videos.
Sign Language Avatars
JASigning
is a virtual signing system that generates sign language performances using virtual human characters. This system evolved from the earlier SiGMLSigning system, which was developed during the ViSiCAST (Bangham et al. 2000; Elliott et al. 2000) and eSIGN (Zwitserlood et al. 2004) projects, and later underwent further development as part of the Dicta-Sign project (Matthes et al. 2012; Efthimiou et al. 2012).
Originally, JASigning relied on Java JNLP apps for standalone use and integration into web pages. However, this approach became outdated due to the lack of support for Java in modern browsers. Consequently, the more recent CWA Signing Avatars (CWASA) system was developed, which is based on HTML5, utilizing JavaScript and WebGL technologies.
SiGML (Signing Gesture Markup Language) (Elliott et al. 2004) is an XML application that enables the transcription of sign language gestures. SiGML builds on HamNoSys, and indeed, one variant of SiGML is essentially an encoding of HamNoSys manual features, accompanied by a representation of non-manual aspects. SiGML is the input notation used by the JASigning applications and web applets. A number of editing tools for SiGML are available, mostly produced by the University of Hamburg.
The system parses the English text into SiGML before mapping it onto a 3D signing avatar that can produce signing. CWASA then uses a large database of pre-defined 3D signing avatar animations, which can be combined to form new sentences. The system includes a 3D editor, allowing users to create custom signing avatars and animations.
PAULA (Davidson 2006)
is a computer-based sign language avatar, initially developed for teaching sign language to hearing adults. The avatar is a 3D model of a person with a sign vocabulary that is manually animated. It takes an ASL utterance as a stream of glosses, performs syntactic and morphological modifications, decides on the appropriate phonemes and timings, and combines the results into a 3D animation of the avatar. Over the years, several techniques were used to make the avatar look more realistic.
Over the years, several advancements have been made to enhance the realism and expressiveness of the PAULA avatar, such as refining the eyebrow motion to appear more natural (Wolfe et al. 2011), combining emotion and co-occurring facial nonmanual signals (Schnepp et al. 2012, 2013), improving smoothness while avoiding robotic movements (McDonald et al. 2016), and facilitating simultaneity (McDonald et al. 2017). Other developments include interfacing with sign language notation systems like AZee (Filhol, McDonald, and Wolfe 2017), enhancing mouthing animation (Johnson, Brumm, and Wolfe 2018; Wolfe et al. 2022), multi-layering facial textures and makeup (Wolfe et al. 2019), and applying adverbial modifiers (Moncrief 2020, 2021).
Additional improvements to PAULA focus on making the avatar more lifelike by relaxing wrist orientations and other extreme “mathematical” angles (Filhol and McDonald 2020), refining hand shape transition, relaxation, and collision (Baowidan 2021), implementing hierarchical phrase transitions (McDonald and Filhol 2021), creating more realistic facial muscle control (McDonald, Johnson, and Wolfe 2022), and supporting geometric relocations (Filhol and McDonald 2022).
SiMAX (“SiMAX - the Sign Language Avatar SiMAX Project Fact Sheet H2020” n.d.)
is a software application developed to transform textual input into 3D animated sign language representations. Utilizing a comprehensive database and the expertise of deaf sign language professionals, SiMAX ensures accurate translations of both written and spoken content. The process begins with the generation of a translation suggestion, which is subsequently reviewed and, if necessary, modified by deaf translators to ensure accuracy and cultural appropriateness. These translations are carried out by a customizable digital avatar that can be adapted to reflect the corporate identity or target audience of the user. This approach offers a cost-effective alternative to traditional sign language video production, as it eliminates the need for expensive film studios and complex video technology typically associated with such productions.
Image and Video Generation Models
Most recently in the field of image and video generation, there have been notable advances in methods such as Style-Based Generator Architecture for Generative Adversarial Networks (Karras, Laine, and Aila 2019; Karras et al. 2020, 2021), Variational Diffusion Models (Kingma et al. 2021), High-Resolution Image Synthesis with Latent Diffusion Models (Rombach et al. 2021), High Definition Video Generation with Diffusion Models (Ho et al. 2022), and High-Resolution Video Synthesis with Latent Diffusion Models (Blattmann et al. 2023). These methods have significantly improved image and video synthesis quality, providing stunningly realistic and visually appealing results.
However, despite their remarkable progress in generating high-quality images and videos, these models trade-off computational efficiency. The complexity of these algorithms often results in slower inference times, making real-time applications challenging. On-device deployment of these models provides benefits such as lower server costs, offline functionality, and improved user privacy. While compute-aware optimizations, specifically targeting hardware capabilities of different devices, could improve the inference latency of these models, Chen et al. (2023) found that optimizing such models on top-of-the-line mobile devices such as the Samsung S23 Ultra or iPhone 14 Pro Max can decrease per-frame inference latency from around 23 seconds to around 12.
ControlNet (L. Zhang and Agrawala 2023) recently presented a neural network structure for controlling pretrained large diffusion models with additional input conditions. This approach enables end-to-end learning of task-specific conditions, even with a small training dataset. Training a ControlNet is as fast as fine-tuning a diffusion model and can be executed on personal devices or scaled to large amounts of data using powerful computation clusters. ControlNet has been demonstrated to augment large diffusion models like Stable Diffusion with conditional inputs such as edge maps, segmentation maps, and keypoints. One of the applications of ControlNet is pose-to-image translation control, which allows the generation of images based on pose information. Although this method has shown promising results, it still requires retraining the model and does not inherently support temporal coherency, which is important for tasks like sign language translation.
In the near future, we can expect many works on controlling video diffusion models directly from text for sign language translation. These models will likely generate visually appealing and realistic videos. However, they may still make mistakes and be limited to scenarios with more training data available. Developing models that can accurately generate sign language videos from text or pose information while maintaining visual quality and temporal coherency will be essential for advancing the field of sign language production.
Pose-to-Gloss
Pose-to-Gloss, also known as sign language recognition, is the task of recognizing a sequence of signs from a sequence of poses. Though some previous works have referred to this as “sign language translation,” recognition merely determines the associated label of each sign, without handling the syntax and morphology of the signed language (C. Padden 1988) to create a spoken language output. Instead, SLR has often been used as an intermediate step during translation to produce glosses from signed language videos.
Jiang et al. (2021) proposed a novel Skeleton Aware Multi-modal Framework with a Global Ensemble Model (GEM) for isolated SLR (SAM-SLR-v2) to learn and fuse multimodal feature representations. Specifically, they use a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics of skeleton keypoints and a Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. The proposed late-fusion GEM fuses the skeleton-based predictions with other RGB and depth-based modalities to provide global information and make an accurate SLR prediction. Jiao et al. (2023) explore co-occurence signals in skeleton data to better exploit the knowledge of each signal for continuous SLR. Specifically, they use Group-specific GCN to abstract skeleton features from co-occurence signals (Body, Hand, Mouth and Hand) and introduce complementary regularization to ensure consistency between predictions based on two complementary subsets of signals. Additionally, they propose a two-stream framework to fuse static and dynamic information. The model demonstrates competitive performance cpmpared to video-to-gloss methods on the RWTH-PHOENIX-Weather-2014 (Koller, Forster, and Ney 2015), RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018) and CSL-Daily (Zhou et al. 2021) datasets.
Dafnis et al. (2022) work on the same modified WLASL dataset as Jiang et al. (2021), but do not require multimodal data input. Instead, they propose a bidirectional skeleton-based graph convolutional network framework with linguistically motivated parameters and attention to the start and end frames of signs. They cooperatively use forward and backward data streams, including various sub-streams, as input. They also use pre-training to leverage transfer learning.
Selvaraj et al. (2022) introduced an open-source OpenHands library, which consists of standardized pose datasets for different existing sign language datasets and trained checkpoints of four pose-based isolated sign language recognition models across six languages (American, Argentinian, Chinese, Greek, Indian, and Turkish). To address the lack of labeled data, they propose self-supervised pretraining on unlabeled data and curate the largest pose-based pretraining dataset on Indian Sign Language (Indian-SL). They established that pretraining is effective for sign language recognition by demonstrating improved fine-tuning performance especially in low-resource settings and high crosslingual transfer from Indian-SL to a few other sign languages.
The work of Kezar, Thomason, and Sehyr (2023), based on the OpenHands library, explicitly recognizes the role of phonology to achieve more accurate isolated sign language recognition (ISLR). To allow additional predictions on phonological characteristics (such as handshape), they combine the phonological annotations in ASL-LEX 2.0 (Sehyr et al. 2021) with signs in the WLASL 2000 ISLR benchmark (Li et al. 2020). Interestingly, Tavella et al. (2022) construct a similar dataset aiming just for phonological property recognition in American Sign Language (ASL).
Gloss-to-Pose
Gloss-to-Pose, subsumed under the task of sign language production, is the task of producing a sequence of poses that adequately represent a sequence of signs written as gloss.
To produce a sign language video, Stoll et al. (2018) constructed a lookup table between glosses and sequences of 2D poses. They aligned all pose sequences at the neck joint of a reference skeleton and grouped all sequences belonging to the same gloss. Then, for each group, they applied dynamic time warping and averaged out all sequences in the group to construct the mean pose sequence. This approach suffers from not having an accurate set of poses aligned to the gloss and from unnatural motion transitions between glosses.
To alleviate the downsides of the previous work, Stoll et al. (2020) constructed a lookup table of gloss to a group of sequences of poses rather than creating a mean pose sequence. They built a Motion Graph (Min and Chai 2012), which is a Markov process used to generate new motion sequences that are representative of natural motion, and selected the motion primitives (sequence of poses) per gloss with the highest transition probability. To smooth that sequence and reduce unnatural motion, they used a Savitzky–Golay motion transition smoothing filter (Savitzky and Golay 1964). Moryossef, Müller, et al. (2023) re-implemented their approach and made it open-source.
Huang et al. (2021) used a new non-autoregressive model to generate a sequence of poses for a sequence of glosses. They argued that existing models like Saunders, Bowden, and Camgöz (2020) are prone to error accumulation and high inference latency due to their autoregressive nature. Their model performs gradual upsampling of the poses, by starting with a pose including only two joints in the first layer, and gradually introducing more keypoints. They evaluated their model on the RWTH-PHOENIX-WEATHER 2014T dataset (Camgöz et al. 2018) using Dynamic Time Warping (DTW) (Berndt and Clifford 1994) to align the poses before computing Mean Joint Error (DTW-MJE). They demonstrated that their model outperforms existing methods in terms of accuracy and speed, making it a promising approach for fast and high-quality sign language production.
Video-to-Gloss
Video-to-Gloss, also known as sign language recognition, is the task of recognizing a sequence of signs from a video.
For this recognition, Cui, Liu, and Zhang (2017) constructs a three-step optimization model. First, they train a video-to-gloss end-to-end model, where they encode the video using a spatio-temporal CNN encoder and predict the gloss using a Connectionist Temporal Classification (CTC) (Graves et al. 2006). Then, from the CTC alignment and category proposal, they encode each gloss-level segment independently, trained to predict the gloss category, and use this gloss video segments encoding to optimize the sequence learning model. Cheng et al. (2020) propose a fully convolutional network for continuous SLR, moving away from LSTM-based methods to achieve end-to-end learning. They introduce a Gloss Feature Enhancement (GFE) module to provide additional rectified supervision and accelerate the training process. Min et al. (2021) attribute the success of iterative training to its ability to reduce overfitting. They propose Visual Enhancement Constraint (VEC) and Visual Alignment Constraint (VAC) to strengthen the visual extractor and align long- and short-term predictions, enabling LSTM-based methods to be trained in an end-to-end manner. They provide a code implementation.
Camgöz et al. (2018) fundamentally differ from that approach and formulate this problem as if it is a natural-language translation problem. They encode each video frame using AlexNet (Krizhevsky, Sutskever, and Hinton 2012), initialized using weights trained on ImageNet (Deng et al. 2009). Then they apply a GRU encoder-decoder architecture with Luong Attention (Luong, Pham, and Manning 2015) to generate the gloss. In follow-up work, N. C. Camgöz et al. (2020b) use a transformer encoder (Vaswani et al. 2017) to replace the GRU and use a CTC to decode the gloss. They show a slight improvement with this approach on the video-to-gloss task.
Adaloglou et al. (2020) perform a comparative experimental assessment of computer vision-based methods for the video-to-gloss task. They implement various approaches from previous research (Camgöz et al. 2017; Cui, Liu, and Zhang 2019; Joze and Koller 2019) and test them on multiple datasets (Huang et al. 2018; Camgöz et al. 2018; Von Agris and Kraiss 2007; Joze and Koller 2019) either for isolated sign recognition or continuous sign recognition. They conclude that 3D convolutional models outperform models using only recurrent networks to capture the temporal information, and that these models are more scalable given the restricted receptive field, which results from the CNN “sliding window” technique.
Momeni, Bull, Prajwal, et al. (2022a) developed a comprehensive pipeline that combines various models to densely annotate sign language videos. By leveraging the use of synonyms and subtitle-signing alignment, their approach demonstrates the value of pseudo-labeling from a sign recognition model for sign spotting. They propose a novel method to increase annotations for both known and unknown classes, relying on in-domain exemplars. As a result, their framework significantly expands the number of confident automatic annotations on the BOBSL BSL sign language corpus (Albanie et al. 2021) from 670K to 5M, and they generously make these annotations publicly available.
Gloss-to-Video
Gloss-to-Video, also known as sign language production, is the task of producing a video that adequately represents a sequence of signs written as gloss.
As of 2020, no research discusses the direct translation task between gloss and video. This lack of discussion results from the computational impracticality of the desired model, leading researchers to refrain from performing this task directly and instead rely on pipeline approaches using intermediate pose representations.
Gloss-to-Text
Gloss-to-Text, also known as sign language translation, is the natural language processing task of translating between gloss text representing sign language signs and spoken language text. These texts commonly differ in terminology, capitalization, and sentence structure.
Camgöz et al. (2018) experimented with various machine-translation architectures and compared using an LSTM (Hochreiter and Schmidhuber 1997) vs. GRU for the recurrent model, as well as Luong attention (Luong, Pham, and Manning 2015) vs. Bahdanau attention (Bahdanau, Cho, and Bengio 2015) and various batch sizes. They concluded that on the RWTH-PHOENIX-Weather-2014T dataset, which was also presented in this work, using GRUs, Luong attention, and a batch size of 1 outperforms all other configurations.
In parallel with the advancements in spoken language machine translation, Yin and Read (2020) proposed replacing the RNN with a Transformer (Vaswani et al. 2017) encoder-decoder model, showing improvements on both RWTH-PHOENIX-Weather-2014T (DGS) and ASLG-PC12 (ASL) datasets both using a single model and ensemble of models. Interestingly, in gloss-to-text, they show that using the sign language recognition (video-to-gloss) system output outperforms using the gold annotated glosses.
Building on the code published by Yin and Read (2020), Moryossef, Yin, et al. (2021) show it is beneficial to pre-train these translation models using augmented monolingual spoken language corpora. They try three different approaches for data augmentation: (1) Back-translation; (2) General text-to-gloss rules, including lemmatization, word reordering, and dropping of words; (3) Language-pair-specific rules augmenting the spoken language syntax to its corresponding sign language syntax. When pretraining, all augmentations show improvements over the baseline for RWTH-PHOENIX-Weather-2014T (DGS) and NCSLGR (ASL).
Text-to-Gloss
Text-to-gloss, an instantiation of sign language translation, is the task of translating between a spoken language text and sign language glosses. It is an appealing area of research because of its simplicity for integrating in existing NMT pipelines, despite recent works such as Yin and Read (2020) and Müller et al. (2023) claim that glosses are an inefficient representation of sign language, and that glosses are not a complete representation of signs (Pizzuto, Rossini, and Russo 2006).
Zhao et al. (2000) used a Tree Adjoining Grammar (TAG)-based system to translate English sentences to American Sign Language (ASL) gloss sequences. They parsed the English text and simultaneously assembled an ASL gloss tree, using Synchronous TAGs (Shieber and Schabes 1990; Shieber 1994), by associating the ASL elementary trees with the English elementary trees and associating the nodes at which subsequent substitutions or adjunctions can occur. Synchronous TAGs have been used for machine translation between spoken languages (Abeille, Schabes, and Joshi 1990), but this was the first application to a signed language.
For the automatic translation of gloss-to-text, Othman and Jemni (2012) identified the need for a large parallel sign language gloss and spoken language text corpus. They developed a part-of-speech-based grammar to transform English sentences from the Gutenberg Project ebooks collection (Lebert 2008) into American Sign Language gloss. Their final corpus contains over 100 million synthetic sentences and 800 million words and is the most extensive English-ASL gloss corpus we know of. Unfortunately, it is hard to attest to the quality of the corpus, as the authors did not evaluate their method on real English-ASL gloss pairs.
Egea Gómez, McGill, and Saggion (2021) presented a syntax-aware transformer for this task, by injecting word dependency tags to augment the embeddings inputted to the encoder. This involves minor modifications in the neural architecture leading to negligible impact on computational complexity of the model. Testing their model on the RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018), they demonstrated that injecting this additional information results in better translation quality.
Video-to-Text
Video-to-text, also known as sign language translation, is the task of translating a raw video to spoken language text.
N. C. Camgöz et al. (2020b) proposed a single architecture to perform this task that can use both the sign language gloss and the spoken language text in joint supervision. They use the pre-trained spatial embeddings from Koller et al. (2019) to encode each frame independently and encode the frames with a transformer. On this encoding, they use a Connectionist Temporal Classification (CTC) (Graves et al. 2006) to classify the sign language gloss. Using the same encoding, they use a transformer decoder to decode the spoken language text one token at a time. They show that adding gloss supervision improves the model over not using it and that it outperforms previous video-to-gloss-to-text pipeline approaches (Camgöz et al. 2018).
Following up, N. C. Camgöz et al. (2020a) propose a new architecture that does not require the supervision of glosses, named “Multi-channel Transformers for Multi-articulatory Sign Language Translation”. In this approach, they crop the signing hand and the face and perform 3D pose estimation to obtain three separate data channels. They encode each data channel separately using a transformer, then encode all channels together and concatenate the separate channels for each frame. Like their previous work, they use a transformer decoder to decode the spoken language text, but unlike their previous work, do not use the gloss as additional supervision. Instead, they add two “anchoring” losses to predict the hand shape and mouth shape from each frame independently, as silver annotations are available to them using the model proposed in Koller et al. (2019). They conclude that this approach is on-par with previous approaches requiring glosses, and so they have broken the dependency upon costly annotated gloss information in the video-to-text task.
Shi et al. (2022) introduce OpenASL, a large-scale American Sign Language (ASL) - English dataset collected from online video sites (e.g., YouTube), and then propose a set of techniques including sign search as a pretext task for pre-training and fusion of mouthing and handshape features to improve translation quality in the absence of glosses and in the presence of visually challenging data.
Yutong Chen, Zuo, et al. (2022) present a two-stream network for sign language recognition (SLR) and translation (SLT), utilizing a dual visual encoder architecture to encode RGB video frames and pose keypoints in separate streams. These streams interact via bidirectional lateral connections. For SLT, the visual encoders based on an S3D backbone (Xie et al. 2018) output to a multilingual translation network using mBART (Liu et al. 2020). The model achieves state-of-the-art performance on the RWTH-PHOENIX-Weather-2014 (Koller, Forster, and Ney 2015), RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018) and CSL-Daily (Zhou et al. 2021) datasets.
B. Zhang, Müller, and Sennrich (2023) propose a multi-modal, multi-task learning approach to end-to-end sign language translation. The model features shared representations for different modalities such as text and video and is trained jointly on several tasks such as video-to-gloss, gloss-to-text, and video-to-text. The approach allows leveraging external data such as parallel data for spoken language machine translation.
Zhou et al. (2023) propose Gloss-Free Sign Language Translation with Visual Alignment Pretraining (GFSLT-VLP) to improve SLT performance through visual-alignment pretraining. In the pretraining stage, they design a pretext task that aligns visual and textual representations within a joint multimodal semantic space, enabling the Visual Encoder to learn language-indicated visual representations. Additionally, they incorporate masked self-supervised learning into the pre-training process to help the text decoder capture the syntactic and semantic properties of sign language sentences more effectively. The approach achieves competitive results on the RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018) and CSL-Daily (Zhou et al. 2021) datasets. They provide a code implementation.
Zhao et al. (2024) introduce CV-SLT, employing conditional variational autoencoders to address the modality gap between video and text. Their approach involves guiding the model to encode visual and textual data similarly through two paths: one with visual data alone and one with both modalities. Using KL divergences, they steer the model towards generating consistent embeddings and accurate outputs regardless of the path. Once the model achieves consistent performance across paths, it can be utilized for translation without gloss supervision. Evaluation on the RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018) and CSL-Daily (Zhou et al. 2021) datasets demonstrates its efficacy. They provide a code implementation based largely on Yutong Chen, Wei, et al. (2022).
Gong et al. (2024) introduce SignLLM, a framework for gloss-free sign language translation that leverages the strengths of Large Language Models (LLMs). SignLLM converts sign videos into discrete and hierarchical representations compatible with LLMs through two modules: (1) The Vector-Quantized Visual Sign (VQ-Sign) module, which translates sign videos into discrete “character-level” tokens, and (2) the Codebook Reconstruction and Alignment (CRA) module, which restructures these tokens into “word-level” representations. During inference, the “word-level” tokens are projected into the LLM’s embedding space, which is then prompted for translation. The LLM itself can be taken “off the shelf” and does not need to be trained. In training, the VQ-Sign “character-level” module is trained with a context prediction task, the CRA “word-level” module with an optimal transport technique, and a sign-text alignment loss further enhances the semantic alignment between sign and text tokens. The framework achieves state-of-the-art results on the RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018) and CSL-Daily (Zhou et al. 2021) datasets without relying on gloss annotations.
Rust et al. (2024) introduce a two-stage privacy-aware method for sign language translation (SLT) at scale, termed Self-Supervised Video Pretraining for Sign Language Translation (SSVP-SLT). The first stage involves self-supervised pretraining of a Hiera vision transformer (Ryali et al. 2023) on large unannotated video datasets (Duarte et al. 2021; Uthus, Tanzer, and Georg 2023). In the second stage, the vision model’s outputs are fed into a multilingual language model (Raffel et al. 2020) for finetuning on the How2Sign dataset (Duarte et al. 2021). To mitigate privacy risks, the framework employs facial blurring during pretraining. They find that while pretraining with blurring hurts performance, some can be recovered when finetuning with unblurred data. SSVP-SLT achieves state-of-the-art performance on How2Sign (Duarte et al. 2021). They conclude that SLT models can be pretrained in a privacy-aware manner without sacrificing too much performance. Additionally, the authors release DailyMoth-70h, a new 70-hour ASL dataset from The Daily Moth.
Text-to-Video
Text-to-Video, also known as sign language production, is the task of producing a video that adequately represents a spoken language text in sign language.
As of 2020, no research discusses the direct translation task between text and video. This lack of discussion results from the computational impracticality of the desired model, leading researchers to refrain from performing this task directly and instead rely on pipeline approaches using intermediate pose representations.
Pose-to-Text
Pose-to-text, also known as sign language translation, is the task of translating a captured or estimated pose sequence to spoken language text.
Ko et al. (2019) demonstrated impressive performance on the pose-to-text task by inputting the pose sequence into a standard encoder-decoder translation network. They experimented both with GRU and various types of attention (Luong, Pham, and Manning 2015; Bahdanau, Cho, and Bengio 2015) and with a Transformer (Vaswani et al. 2017), and showed similar performance, with the transformer underperforming on the validation set and overperforming on the test set, which consists of unseen signers. They experimented with various normalization schemes, mainly subtracting the mean and dividing by the standard deviation of every individual keypoint either concerning the entire frame or the relevant “object” (Body, Face, and Hand).
Jiao, Min, and Chen (2024) propose a visual alignment pre-training framework for gloss-free sign language translation. Specifically, they adopt CoSign-1s (Jiao et al. 2023) to obtain skeleton features from estimated pose sequences and a pretrained text encoder to obtain corresponding textual features. During pretraining, these visual and textual features are aligned in a greedy manner. In the finetuning stage, they replace the shallow translation module used in pretraining with a pretrained translation module. This skeleton-based approach achieves state-of-the-art results on the RWTH-PHOENIX-Weather-2014T (Camgöz et al. 2018), CSL-Daily (Zhou et al. 2021), OpenASL (Shi et al. 2022), and How2Sign (Duarte et al. 2021) datasets without relying on gloss annotations.
Text-to-Pose
Text-to-Pose, also known as sign language production, is the task of producing a sequence of poses that adequately represent a spoken language text in sign language, as an intermediate representation to overcome challenges in animation. Most efforts use poses as an intermediate representation to overcome the challenges in generating videos directly, with the goal of using computer animation or pose-to-video models to perform video production.
Saunders, Camgöz, and Bowden (2020b) proposed Progressive Transformers, a model to translate from discrete spoken language sentences to continuous 3D sign pose sequences in an autoregressive manner. Unlike symbolic transformers (Vaswani et al. 2017), which use a discrete vocabulary and thus can predict an end-of-sequence (EOS) token in every step, the progressive transformer predicts a counter ∈ [0, 1] in addition to the pose. In inference time, counter = 1 is considered the end of the sequence. They tested their approach on the RWTH-PHOENIX-Weather-2014T dataset (Camgöz et al. 2018) using OpenPose 2D pose estimation, uplifted to 3D (Zelinka and Kanis 2020), and showed favorable results when evaluating using back-translation from the generated poses to spoken language. They further showed (Saunders, Bowden, and Camgöz 2020) that using an adversarial discriminator between the ground truth poses and the generated poses, conditioned on the input spoken language text, improves the production quality as measured using back-translation.
To overcome the issues of under-articulation seen in the above works, Saunders, Camgöz, and Bowden (2020a) expanded on the progressive transformer model using a Mixture Density Network (MDN) (Bishop 1994) to model the variation found in sign language. While this model underperformed on the validation set, compared to previous work, it outperformed on the test set.
Zelinka and Kanis (2020) presented a similar autoregressive decoder approach, with added dynamic-time-warping (DTW) and soft attention. They tested their approach on Czech Sign Language weather data extracted from the news, which is not manually annotated, or aligned to the spoken language captions, and showed their DTW is advantageous for this kind of task.
Xiao, Qin, and Yin (2020) closed the loop by proposing a text-to-pose-to-text model for the case of isolated sign language recognition. They first trained a classifier to take a sequence of poses encoded by a BiLSTM and classify the relevant sign, then proposed a production system to take a single sign and sample a constant length sequence of 50 poses from a Gaussian Mixture Model. These components are combined such that given a sign class y, a pose sequence is generated, then classified back into a sign class ŷ, and the loss is applied between y and ŷ, and not directly on the generated pose sequence. They evaluate their approach on the CSL dataset (Huang et al. 2018) and show that their generated pose sequences almost reach the same classification performance as the reference sequences.
Due to the need for more suitable automatic evaluation methods for generated signs, existing works resort to measuring back-translation quality, which cannot accurately capture the quality of the produced signs nor their usability in real-world settings. Understanding how distinctions in meaning are created in signed language may help develop a better evaluation method.
Notation-to-Text
Jiang et al. (2023) explore text-to-text sign to spoken language translation, with SignWriting as the chosen sign language notation system. Despite SignWriting usually represented in 2D, they use the 1D Formal SignWriting specification and propose a neural factored machine translation approach to encode sequences of SignWriting graphemes as well as their positions in the 2D space. They verify the proposed approach on the SignBank dataset in both a bilingual setup (American Sign Language to English) and two multilingual setups (4 and 21 language pairs, respectively). They apply several low-resource machine translation techniques used to improve spoken language translation to similarly improve the performance of sign language translation. Their findings validate the use of an intermediate text representation for signed language translation, and pave the way for including sign language translation in natural language processing research.
Text-to-Notation
Jiang et al. (2023) also explore the reverse translation direction, i.e., text to SignWriting translation. They conduct experiments under a same condition of their multilingual SignWriting to text (4 language pairs) experiment, and again propose a neural factored machine translation approach to decode the graphemes and their position separately. They borrow BLEU from spoken language translation to evaluate the predicted graphemes and mean absolute error to evaluate the positional numbers.
Walsh, Saunders, and Bowden (2022) explore Text to HamNoSys (T2H) translation, with HamNoSys as the target sign language notation system. They experiment with direct T2H and Text to Gloss to HamNoSys (T2G2H) on a subset of the data from the MEINE DGS dataset (Hanke et al. 2020), where all glosses are mapped to HamNoSys by a dictionary lookup. They find that direct T2H translation results in higher BLEU (it still needs to be clarified how well BLEU represents the quality of HamNoSys translations, though). They encode HamNoSys with BPE (Sennrich, Haddow, and Birch 2016), outperforming character-level and word-level tokenization. They also leverage BERT to create better sentence-level embeddings and use HamNoSys to extract the hand shapes of a sign as additional supervision during training.
Notation-to-Pose
Arkushin, Moryossef, and Fried (2023) proposed Ham2Pose, a model to animate HamNoSys into a sequence of poses. They first encode the HamNoSys into a meaningful “context” representation using a transform encoder, and use it to predict the length of the pose sequence to be generated. Then, starting from a still frame they used an iterative non-autoregressive decoder to gradually refine the sign over T steps, In each time step t from T to 1, the model predicts the required change from step t to step t − 1. After T steps, the pose generator outputs the final pose sequence. Their model outperformed previous methods like Saunders, Camgöz, and Bowden (2020b), animating HamNoSys into more realistic sign language sequences.
Evaluation Metrics
Methods for automatic evaluation of sign language processing are typically dependent only on the output and independent of the input.
Text output
For tasks that output spoken language text, standard machine translation metrics such as BLEU, chrF, or COMET are commonly used.
Gloss Output
Gloss outputs can be automatically scored as well, though not without issues. In particular, Müller et al. (2023) analysed this and provide a series of recommendations (see the section on “Glosses”, above).
Pose Output
For translation from spoken languages to signed languages, automatic evaluation metrics are an open line of research, though some metrics involving back-translation have been developed (see Text-to-Pose and Notation-to-Pose, above).
Naively, works in this domain have used metrics such as Mean Squared Error (MSE) or Average Position Error (APE) for pose outputs (Ahuja and Morency 2019; Ghosh et al. 2021; Petrovich, Black, and Varol 2022). However, these metrics have significant limitations for Sign Language Production.
For example, MSE and APE do not account for variations in sequence length. In practice, the same sign will not always take exactly the same amount of time to produce, even by the same signer. To address time variation, Huang et al. (2021) introduced a metric for pose sequence outputs based on measuring the distance between generated and reference pose sequences at the joint level using dynamic time warping, termed DTW-MJE (Dynamic Time Warping - Mean Joint Error). However, this metric did not clearly address how to handle missing keypoints. Arkushin, Moryossef, and Fried (2023) experimented with multiple evaluation methods, and proposed adding a distance function that accounts for these missing keypoints. They applied this function with normalization of keypoints, naming their metric nDTW-MJE.
Multi-Channel Block output
As an alternative to gloss sequences, Kim et al. (2024) proposed a multi-channel output representation for sign languages and introduced SignBLEU, a BLEU-like scoring method for these outputs. Instead of a single linear sequence of glosses, the representation segments sign language output into multiple linear channels, each containing discrete “blocks”. These blocks represent both manual and non-manual signals, for example, one for each hand and others for various non-manual signals like eyebrow movements. The blocks are then converted to n-grams: temporal grams capture sequences within a channel, and channel grams capture co-occurrences across channels. The SignBLEU score is then calculated for these n-grams of varying orders. They evaluated SignBLEU on the DGS Corpus v3.0 (Konrad et al. 2020; Prillwitz et al. 2008), NIASL2021 (Huerta-Enochian et al. 2022), and NCSLGR (Neidle and Sclaroff 2012; Vogler and Neidle 2012) datasets, comparing it with single-channel (gloss) metrics such as BLEU, TER, chrF, and METEOR, as well as human evaluations by native signers. The authors found that SignBLEU consistently correlated better to human evaluation than these alternatives. However, one limitation of this approach is the lack of suitable datasets. The authors reviewed a number of sign language corpora, noting the relative scarcity of multi-channel annotations. The source code for SignBLEU is available. As with SacreBLEU (Post 2018), the code can generate “version signature” strings summarizing key parameters, to enhance reproducibility.
Sign Language Retrieval
Sign Language Retrieval is the task of finding a particular data item, given some input. In contrast to translation, generation or production tasks, there can exist a correct corresponding piece of data already, and the task is to find it out of many, if it exists. Metrics used include retrieval at Rank K (R@K, higher is better) and median rank (MedR, lower is better).
Athitsos et al. (2010) present one of the early works on this task, using a method based on hand centroids and dynamic time warping to enable users to submit videos of a sign and thus query within the ASL Lexicon Video Dataset (Athitsos et al. 2008).
Zhang and Zhang (2010) provide another early method for video-based querying. They use classical image feature extraction methods to calculate movement trajectories. They then use modified string edit distances between these trajectories as a way to find similar videos.
Coster and Dambre (2023) present a method to query sign language dictionaries using dense vector search. They pretrain a Sign Language Recognition model on a subset of the VGT corpus (Van Herreweghe, Mieke and Vermeerbergen, Myriam and Demey, Eline and De Durpel, Hannes and Nyffels, Hilde and Verstraete, Sam, n.d.) to embed sign inputs. Once the encoder is trained, they use it to generate embeddings for all dictionary signs. When a user submits a query video, the system compares the input embeddings with those of the dictionary entries using Euclidean distance. Tests on a proof-of-concept Flemish Sign Language dictionary show that the system can successfully retrieve a limited vocabulary of signs, including some not in the training set.
Cheng et al. (2023) introduce a video-to-text and text-to-video retrieval method using cross-lingual contrastive learning. Inspired by transfer learning from sign-spotting/segmentation models (Jui, Bejarano, and Rivas 2022; Duarte et al. 2022), the authors employ a “domain-agnostic” I3D encoder, pretrained on large-scale sign language datasets for the sign-spotting task (Varol et al. 2021). On target datasets with continuous signing videos, they use this model with a sliding window to identify high confidence predictions, which are then used to finetune a “domain-aware” sign-spotting encoder. The two encoders each pre-extract features from videos, which are then fused via a weighted sum. Cross-lingual contrastive learning (Radford et al. 2021) is then applied to align the extracted features with paired texts within a shared embedding space. This allows the calculation of similarity scores between text and video embeddings, and thus retrieval in either direction. Evaluations on the How2Sign (Duarte et al. 2021) and RWTH-PHOENIX-Weather 2014T (Camgöz et al. 2018) datasets demonstrate improvement over the previous state-of-the-art (Duarte et al. 2022). Baseline retrieval results are also provided for the CSL-Daily dataset (Zhou et al. 2021).
Fingerspelling
Fingerspelling is spelling a word letter-by-letter, borrowing from the spoken language alphabet (Battison 1978; Wilcox 1992; Brentari and Padden 2001; Patrie and Johnson 2011). This phenomenon, found in most signed languages, often occurs when there is no previously agreed-upon sign for a concept, like in technical language, colloquial conversations involving names, conversations involving current events, emphatic forms, and the context of code-switching between the signed language and the corresponding spoken language (Padden 1998; Montemurro and Brentari 2018). The relative amount of fingerspelling varies between signed languages, and for American Sign Language (ASL), accounts for 12-35% of the signed content (Padden and Gunsauls 2003).
Patrie and Johnson (2011) described the following terminology to describe three different forms of fingerspelling:
- Careful—slower spelling where each letter pose is clearly formed.
- Rapid—quick spelling where letters are often not completed and contain remnants of other letters in the word.
- Lexicalized—a sign produced by often using no more than two letter-hand-shapes (Battison 1978).
For example, lexicalizedALLusesAandL, lexicalizedBUZZusesBandZ, etc…
Recognition
Fingerspelling recognition, a sub-task of sign language recognition, is the task of recognizing fingerspelled words from a sign language video.
Shi et al. (2018) introduced a large dataset available for American Sign Language fingerspelling recognition. This dataset includes both the “careful” and “rapid” forms of fingerspelling collected from naturally occurring videos “in the wild”, which are more challenging than studio conditions. They trained a baseline model to take a sequence of images cropped around the signing hand and either use an autoregressive decoder or a CTC. They found that the CTC outperformed the autoregressive decoder model, but both achieved poor recognition rates (35-41% character level accuracy) compared to human performance (around 82%).
In follow-up work, Shi et al. (2019) collected nearly an order-of-magnitude larger dataset and designed a new recognition model. Instead of detecting the signing hand, they detected the face and cropped a large area around it. Then, they performed an iterative process of zooming in to the hand using visual attention to retain sufficient information in high resolution of the hand. Finally, like their previous work, they encoded the image hand crops sequence and used a CTC to obtain the frame labels. They showed that this method outperformed their original “hand crop” method by 4% and that they could achieve up to 62.3% character-level accuracy using the additional data collected. Looking through this dataset, we note that the videos in the dataset were taken from longer videos, and as they were cut, they did not retain the signing before the fingerspelling. This context relates to language modeling, where at first, one fingerspells a word carefully, and when repeating it, might fingerspell it rapidly, but the interlocutors can infer they are fingerspelling the same word.
Production
Fingerspelling production, a sub-task of sign language production, is the task of producing a fingerspelling video for words.
In its basic form, “careful” fingerspelling production can be trivially solved using pre-defined letter handshapes interpolation. Adeline (2013) demonstrated this approach for American Sign Language and English fingerspelling. They rigged a hand armature for each letter in the English alphabet (N = 26) and generated all (N2 = 676) transitions between every two letters using interpolation or manual animation. Then, to fingerspell entire words, they chain pairs of letter transitions. For example, for the word “CHLOE”, they would chain the following transitions sequentially: #C CH HL LO OE E#.
However, to produce life-like animations, one must also consider the rhythm and speed of holding letters, and transitioning between letters, as those can affect how intelligible fingerspelling motions are to an interlocutor (Wilcox (1992)). Wheatland et al. (2016) analyzed both “careful” and “rapid” fingerspelling videos for these features. They found that for both forms of fingerspelling, on average, the longer the word, the shorter the transition and hold time. Furthermore, they found that less time is spent on middle letters on average, and the last letter is held on average for longer than the other letters in the word. Finally, they used this information to construct an animation system using letter pose interpolation and controlled the timing using a data-driven statistical model.
Pretraining and Representation-learning
In this paradigm, rather than targeting a specific task (e.g. pose-to-text), the aim is to learn a generally-useful Sign Language Understanding model or representation which can be applied or finetuned to specific downstream tasks.
Hu et al. (2023) introduce SignBERT+, a self-supervised pretraining method for sign language understanding (SLU) based on masked modeling of pose sequences. This is an extension of their earlier SignBERT (H. Hu, Zhao, et al. 2021), with several improvements. For pretraining they extract pose sequences from over 230k videos using MMPose (Contributors 2020). They then perform multi-level masked modeling (joints, frames, clips) on these sequences, integrating a statistical hand model (Romero, Tzionas, and Black 2017) to constrain the decoder’s predictions for anatomical realism and enhanced accuracy. Validation on isolated SLR (MS-ASL (Joze and Koller 2019), WLASL (Li et al. 2020), SLR500 (Huang et al. 2019)), continuous SLR (RWTH-PHOENIX-Weather 2014 (Koller, Forster, and Ney 2015)), and SLT (RWTH-PHOENIX-Weather 2014T (Camgöz et al. 2018)) demonstrates state-of-the-art performance.
Zhao et al. (2023) introduce BEST (BERT Pre-training for Sign Language Recognition with Coupling Tokenization), a pre-training method based on masked modeling of pose sequences using a coupled tokenization scheme. This method takes pose triplet units (left hand, right hand, and upper-body with arms) as inputs, each tokenized into discrete codes (Oord, Vinyals, and Kavukcuoglu 2017) that are then coupled together. Masked modeling is then applied, where any or all components of the triplet (left hand, right hand, or upper-body) may be masked, to learn hierarchical correlations among them. Unlike Hu et al. (2023), BEST does not mask multi-frame pose sequences or individual joints. The authors validate their pre-training method on isolated sign recognition (ISR) tasks using MS-ASL (Joze and Koller 2019), WLASL (Li et al. 2020), SLR500 (Huang et al. 2019), and NMFs-CSL (H. Hu, Zhou, et al. 2021). Besides pose-to-gloss, they also experiment with video-to-gloss tasks via fusion with I3D (Carreira and Zisserman 2017). Results on these datasets demonstrate state-of-the-art performance compared to previous methods and are comparable to those of SignBERT+ (Hu et al. 2023).
Annotation Tools
ELAN - EUDICO Linguistic Annotator
ELAN (Wittenburg et al. 2006) is an annotation tool for audio and video recordings. With ELAN, a user can add an unlimited number of textual annotations to audio and/or video recordings. An annotation can be a sentence, word, gloss, comment, translation, or description of any feature observed in the media. Annotations can be created on multiple layers, called tiers, which can be hierarchically interconnected. An annotation can either be time-aligned to the media or refer to other existing annotations. The content of annotations consists of Unicode text, and annotation documents are stored in an XML format (EAF). ELAN is open source (GPLv3), and installation is available for Windows, macOS, and Linux. PyMPI (Lubbers and Torreira 2013) allows for simple python interaction with Elan files.
iLex
iLex (Hanke 2002) is a tool for sign language lexicography and corpus analysis, that combines features found in empirical sign language lexicography and sign language discourse transcription. It supports the user in integrated lexicon building while working on the transcription of a corpus and offers several unique features considered essential due to the specific nature of signed languages. iLex binaries are available for macOS.
SignStream
SignStream (Neidle, Sclaroff, and Athitsos 2001) is a tool for linguistic annotations and computer vision research on visual-gestural language data SignStream installation is available for macOS and is distributed under an MIT license.
Anvil - The Video Annotation Research Tool
Anvil (Kipp 2001) is a free video annotation tool, offering multi-layered annotation based on a user-defined coding scheme. In Anvil, the annotator can see color-coded elements on multiple tracks in time alignment. Some special features are cross-level links, non-temporal objects, timepoint tracks, coding agreement analysis, 3D viewing of motion capture data and a project tool for managing whole corpora of annotation files. Anvil installation is available for Windows, macOS, and Linux.
Resources
Dataset Papers
Research papers which do not necessarily contribute new theory or architectures are actually important and useful enablers of other research. Furthermore, the advancement of the dataset creation process itself is important, and the pipeline of creation and curation is a potential target for improvements and advancements.
Joshi, Agrawal, and Modi (2023) introduce ISLTranslate, a large translation dataset for Indian Sign Language based on publicly available educational videos intended for hard-of-hearing children, which happen to contain both Indian Sign Language and English audio voiceover conveying the same content. They use a speech-to-text model to transcribe the audio content, which they later manually corrected with the help of accompanying books also containing the same content. They also use MediaPipe to extract pose features, and have a certified ISL signer validate a small portion of the sign-text pairs. They provide a baseline based on the architecture proposed in N. C. Camgöz et al. (2020b), and provide code.
Bilingual dictionaries
for signed language (Mesch and Wallin 2012; Fenlon, Cormier, and Schembri 2015; Crasborn et al. 2016; Gutierrez-Sigut et al. 2016) map a spoken language word or short phrase to a signed language video. One notable dictionary, SpreadTheSign is a parallel dictionary containing around 25,000 words with up to 42 different spoken-signed language pairs and more than 600,000 videos in total. Unfortunately, while dictionaries may help create lexical rules between languages, they do not demonstrate the grammar or the usage of signs in context.
Fingerspelling corpora
usually consist of videos of words borrowed from spoken languages that are signed letter-by-letter. They can be synthetically created (Dreuw et al. 2006) or mined from online resources (Shi et al. 2018, 2019). However, they only capture one aspect of signed languages.
Isolated sign corpora
are collections of annotated single signs. They are synthesized (Ebling et al. 2018; Huang et al. 2018; Sincan and Keles 2020; Hassan et al. 2020) or mined from online resources (Joze and Koller 2019; Li et al. 2020), and can be used for isolated sign language recognition or contrastive analysis of minimal signing pairs (Imashev et al. 2020). However, like dictionaries, they do not describe relations between signs, nor do they capture coarticulation during the signing, and are often limited in vocabulary size (20-1000 signs).
Continuous sign corpora
contain parallel sequences of signs and spoken language. Available continuous sign corpora are extremely limited, containing 4-6 orders of magnitude fewer sentence pairs than similar corpora for spoken language machine translation (Arivazhagan et al. 2019). Moreover, while automatic speech recognition (ASR) datasets contain up to 50,000 hours of recordings (Pratap et al. 2020), the most extensive continuous sign language corpus contains only 1,150 hours, and only 50 of them are publicly available (Hanke et al. 2020). These datasets are usually synthesized (Databases 2007; Crasborn and Zwitserlood 2008; Ko et al. 2019; Hanke et al. 2020) or recorded in studio conditions (Forster et al. 2014; Camgöz et al. 2018), which does not account for noise in real-life conditions. Moreover, some contain signed interpretations of spoken language rather than naturally-produced signs, which may not accurately represent native signing since translation is now a part of the discourse event.
Availability
Unlike the vast amount and diversity of available spoken language resources that allow various applications, sign language resources are scarce and, currently only support translation and production. Unfortunately, most of the sign language corpora discussed in the literature are either not available for use or available under heavy restrictions and licensing terms. Furthermore, sign language data is especially challenging to anonymize due to the importance of facial and other physical features in signing videos, limiting its open distribution. Developing anonymization with minimal information loss or accurate anonymous representations is a promising research direction.
Collect Real-World Data
Data is essential to develop any of the core NLP tools previously described, and current efforts in SLP are often limited by the lack of adequate data. We discuss the considerations to keep in mind when building datasets, the challenges of collecting such data, and directions to facilitate data collection.
What is Good Signed Language Data?
For SLP models to be deployable, they must be developed using data that represents the real world accurately. What constitutes an ideal signed language dataset is an open question, we suggest including the following requirements: (1) a broad domain; (2) sufficient data and vocabulary size; (3) real-world conditions; (4) naturally produced signs; (5) a diverse signer demographic; (6) native signers; and when applicable, (7) dense annotations.
To illustrate the importance of data quality during modeling, Yin et al. (2021) first take as an example a current benchmark for SLP, the RWTH-PHOENIX-Weather 2014T dataset (Camgöz et al. 2018) of German Sign Language, that does not meet most of the above criteria: it is restricted to the weather domain (1); contains only around 8K segments with 1K unique signs (2); filmed in studio conditions (3); interpreted from German utterances (4); and signed by nine Caucasian interpreters (5,6). Although this dataset successfully addressed data scarcity issues at the time and successfully rendered results comparable and fueled competitive research, it does not accurately represent signed languages in the real world. On the other hand, the Public DGS Corpus (Hanke et al. 2020) is an open-domain (1) dataset consisting of 50 hours of natural signing (4) by 330 native signers from various regions in Germany (5,6), annotated with glosses, HamNoSys and German translations (7), meeting all but two requirements we suggest.
They train a gloss-to-text sign language translation transformer (Yin and Read 2020) on both datasets. On RWTH-PHOENIX-Weather 2014T, they obtain 22.17 BLEU on testing; on Public DGS Corpus, they obtain a mere BLEU. Although Transformers achieve encouraging results on RWTH-PHOENIX-Weather 2014T (Saunders, Camgöz, and Bowden 2020b; N. C. Camgöz et al. 2020a), they fail on more realistic, open-domain data. These results reveal that, for real-world applications, we need more data to train such models. At the same time, available data is severely limited in size; less data-hungry and more linguistically-informed approaches may be more suitable. This experiment reveals how it is crucial to use data that accurately represent the complexity and diversity of signed languages to precisely assess what types of methods are suitable and how well our models would deploy to the real world.
Challenges of Data Collection
Collecting and annotating signed data in line with the ideal requires more resources than speech or text data, taking up to 600 minutes per minute of an annotated signed language video (Hanke et al. 2020). Moreover, annotation usually requires specific knowledge and skills, which makes recruiting or training qualified annotators challenging. Additionally, there is little existing signed language data in the wild openly licensed for use, especially from native signers that are not interpretations of speech. Therefore, data collection often requires significant efforts and costs of on-site recording.
Automating Annotation
One helpful research direction for collecting more data that enables the development of deployable SLP models is creating tools that can simplify or automate parts of the collection and annotation process. One of the most significant bottlenecks in obtaining more adequate signed language data is the time and scarcity of experts required to perform annotation. Therefore, tools that perform automatic parsing, detection of frame boundaries, extraction of articulatory features, suggestions for lexical annotations, and allow parts of the annotation process to be crowdsourced to non-experts, to name a few, have a high potential to facilitate and accelerate the availability of good data.
Practice Deaf Collaboration
Finally, when working with signed languages, it is vital to keep in mind this technology should benefit and they need. Researchers in SLP should acknowledge that signed languages belong to the Deaf community and avoid exploiting their language as a commodity (Bird 2020).
Solving Real Needs
Many efforts in SLP have developed intrusive methods (e.g., requiring signers to wear special gloves), which are often rejected by signing communities and therefore have limited real-world value. Such efforts are often marketed to perform “sign language translation” when they, in fact, only identify fingerspelling or recognize a minimal set of isolated signs at best. These approaches oversimplify the rich grammar of signed languages, promote the misconception that signs are solely expressed through the hands, and are considered by the Deaf community as a manifestation of audism, where it is the signers who must make the extra effort to wear additional sensors to be understood by non-signers (Erard 2017). To avoid such mistakes, we encourage close Deaf involvement throughout the research process to ensure that we direct our efforts toward applications that will be adopted by signers and do not make false assumptions about signed languages or the needs of signing communities.
Building Collaboration
Deaf collaborations and leadership are essential for developing signed language technologies to ensure they address the community’s needs and will be adopted, not relying on misconceptions or inaccuracies about signed language (Harris, Holmes, and Mertens 2009; Annelies Kusters, De Meulder, and O’Brien 2017). Hearing researchers cannot relate to the deaf experience or fully understand the context in which the tools being developed would be used, nor can they speak for the deaf. Therefore, we encourage creating a long-term collaborative environment between signed language researchers and users so that deaf users can identify meaningful challenges and provide insights on the considerations to take while researchers cater to the signers’ needs as the field evolves. We also recommend reaching out to signing communities for reviewing papers on signed languages to ensure an adequate evaluation of this type of research results published at academic venues. There are several ways to connect with Deaf communities for collaboration: one can seek deaf students in their local community, reach out to schools for the deaf, contact deaf linguists, join a network of researchers of sign-related technologies, and/or participate in deaf-led projects.
Downloading
Currently, there is no easy way or agreed-upon format to download and load sign language datasets, and as such, evaluation of these datasets is scarce. As part of this work, we streamlined the loading of available datasets using Tensorflow Datasets (authors 2019). This tool allows researchers to load large and small datasets alike with a simple command and be comparable to other works. We make these datasets available using a custom library, Sign Language Datasets (Moryossef and Müller 2021).
import tensorflow_datasets as tfds
import sign_language_datasets.datasets
# Loading a dataset with default configuration
aslg_pc12 = tfds.load("aslg_pc12")
# Loading a dataset with custom configuration
from sign_language_datasets.datasets.config import SignDatasetConfig
config = SignDatasetConfig(
name="videos_and_poses256x256:12",
# Specific version
version="3.0.0",
# Download, and load dataset videos
include_video=True,
# Load videos at constant, 12 fps
fps=12,
# Convert videos to a constant resolution, 256x256
resolution=(256, 256),
# Download and load Holistic pose estimation
include_pose="holistic")
rwth_phoenix2014_t = tfds.load(
name='rwth_phoenix2014_t',
builder_kwargs=dict(config=config))Furthermore, we follow a unified interface when possible, making attributes the same and comparable between datasets:
{
"id": tfds.features.Text(),
"signer": tfds.features.Text() | tf.int32,
"video": tfds.features.Video(
shape=(None, HEIGHT, WIDTH, 3)),
"depth_video": tfds.features.Video(
shape=(None, HEIGHT, WIDTH, 1)),
"fps": tf.int32,
"pose": {
"data": tfds.features.Tensor(
shape=(None, 1, POINTS, CHANNELS),
dtype=tf.float32),
"conf": tfds.features.Tensor(
shape=(None, 1, POINTS),
dtype=tf.float32)
},
"gloss": tfds.features.Text(),
"text": tfds.features.Text()
}List of Datasets
The following table contains a curated list of datasets, including various signed languages and data formats:
🎥 Video | 👋 Pose | 👄 Mouthing | ✍ Notation | 📋 Gloss | 📜 Text | 🔊 Speech
| Dataset | Publication | Language | Features | #Signs | #Samples | #Signers | License |
|---|---|---|---|---|---|---|---|
| ASL-100-RGBD | Hassan et al. (2020) | American | 🎥👋📋 | 100 | 4,150 Tokens | 22 | Authorized Academics |
| ASL-Homework-RGBD | Hassan et al. (2022) | American | 🎥👋📋 | 935 | 45 | Authorized Academics | |
| ASL-LEX | Sehyr et al. (2021) | American | 📋 | 2,723 | 2723 glosses+linguistic annotations, video downloads not allowed | CC BY-NC 4.0 | |
| ASLG-PC12 💾 | Othman and Jemni (2012) | American (Synthetic) | 📋📜 | > 100,000,000 Sentences | N/A | Sample Available (1, 2) | |
| ASLLVD | Athitsos et al. (2008);Athitsos et al. (2010) | American | 📋🎥 | 3,000 | 12,000 Samples | 4 | Attribution |
| AUSLAN | Johnston (2008) | Australian | 🎥📋 | 1,100 Videos | 100 | Attribution | |
| AUTSL 💾 | Sincan and Keles (2020) | Turkish | 🎥📋 | 226 | 36,302 Samples | 43 | Codalab |
| BOBSL | Momeni, Bull, Prajwal, et al. (2022b) | British | 🎥📜 | 2,281 | 1.2M Sentences | 37 | non-commercial authorized academics |
| BosphorusSign | Camgöz et al. (2016) | Turkish | 🎥👋📋 | 855 (595 public) | 22k+ (22,670 public) | 6 | Research purpose on request |
| BosphorusSign22k | Özdemir et al. (2020) | Turkish | 🎥📋👋👋 | 744 | 22542 | 6 | Research purpose on request |
| BSL Corpus 💾 | Schembri et al. (2013) | British | 🎥📋📜 | 40,000 Lexical Items | 249 | Partially Restricted | |
| CDPSL | Łacheta and PawełRutkowski (2014) | Polish | 🎥✍📜 | 300 hours | |||
| ChicagoFSWild 💾 | Shi et al. (2018) | American | 🎥📜 | 26 | 7,304 Sequences | 160 | Public |
| ChicagoFSWild+ 💾 | Shi et al. (2019) | American | 🎥📜 | 26 | 55,232 Sequences | 260 | Public |
| Content4All | Camgöz et al. (2021) | Swiss-German, Flemish | 🎥👋📜📜 | 190 Hours | CC BY-NC-SA 4.0 | ||
| Corpus NGT 💾 | Crasborn and Zwitserlood (2008) | Netherlands | 🎥🎥📋📜 | ~3k | ~2375 sessions | ~90 | CC BY-NC-SA 4.0 |
| DEVISIGN | Chai, Wang, and Chen (2014) | Chinese | 👋🎥📋 | 2,000 | 24,000 Samples | 8 | Research purpose on request |
| Dicta-Sign 💾 | Matthes et al. (2012) | Multilingual | ✍📋🎥 | 6-8 Hours (/Participant) | 16-18 /Language | ||
| How2Sign 💾 | Duarte et al. (2021) | American | 🎥👋📋📜🔊 | 16,000 | 79 hours (35,000 sentences) | 11 | CC BY-NC 4.0 |
| ISL-HS | Oliveira et al. (2017) | Irish | 🎥📋 | 23 | 468 videos->58,114 images->23 handshapes | 6 | |
| ISLTranslate | Joshi, Agrawal, and Modi (2023) | Indian | 🎥📜👋 | 11,000 | 31k sentences | CC BY-NC 4.0 | |
| K-RSL | Imashev et al. (2020) | Kazakh-Russian | 🎥👋📜 | 600 | 28,250 Videos | 10 | Attribution |
| KETI | Ko et al. (2019) | Korean | 🎥👋📋📜 | 524 | 14,672 Videos | 14 | TODO (emailed Sang-Ki Ko) |
| KRSL-OnlineSchool | Mukushev et al. (2022) | Kazakh-Russian | 🎥📋📜 | 890 Hours (1M sentences) | 7 | ||
| LSA-T | Dal Bianco et al. (2023) | Argentina | 🎥📜👋 | 14,880 sentences | 103 | MIT | |
| LSE-SIGN | Gutierrez-Sigut et al. (2016) | Spanish | TODO | 2,400 | 2,400 Samples | 2 | Custom |
| MS-ASL | Joze and Koller (2019) | American | 🎥📋 | 1,000 | 25,513 (~25 hours) | 222 | Public |
| NCSLGR 💾 | Databases (2007) | American | 🎥📋📜 | 1,875 sentences | 4 | TODO | |
| NMFs-CSL | H. Hu, Zhou, et al. (2021) | Chinese | 📋🎥 | 1,067 | 32,010 videos | 10 | Research purpose on request |
| PopSign ASL v1.0 | Starner et al. (2023) | American | 🎥📋 | 250 | 175023 | 47 | |
| Public DGS Corpus 💾 | Prillwitz et al. (2008) | German | 🎥🎥👋👄✍📋📜📜 | 50 Hours | 330 | Custom | |
| RVL-SLLL ASL | Martínez et al. (2002) | American | TODO | 104 | 2,576 Videos | 14 | Research Attribution |
| RWTH Fingerspelling | Dreuw et al. (2006) | German | 🎥📜 | 35 | 1,400 single-char videos | 20 | |
| RWTH-BOSTON-104 | Dreuw et al. (2008) | American | 🎥📜 | 104 | 201 Sentences | 3 | |
| RWTH-PHOENIX-Weather T 💾 | Camgöz et al. (2018) | German | 🎥📋📜 | 1,231 | 8,257 Sentences | 9 | CC BY-NC-SA 3.0 |
| S-pot | Viitaniemi et al. (2014) | Finnish | TODO | 1,211 | 5,539 Videos | 5 | Permission |
| Sign2MINT 💾 | 2021 | German | 🎥✍📜 | 740 | 1135 | CC BY-NC-SA 3.0 DE | |
| SignBank 💾 | Multilingual | 🎥✍📜 | 222148 | ||||
| SignBD-Word | Sams, Akash, and Rahman (2023) | Bangla | 🎥👋 | 200 | 6000 videos | 16 | |
| SIGNOR | Vintar, Jerko, and Kulovec (2012) | Slovene | 🎥👄✍📋📜 | 80 | TODO emailed Špela | ||
| SIGNUM | Von Agris and Kraiss (2007) | German | TODO | 450 | 15,600 Sequences | 20 | |
| SMILE | Ebling et al. (2018) | Swiss-German | TODO | 100 | 9,000 Samples | 30 | Custom |
| SSL Corpus | Öqvist, Riemer Kankkonen, and Mesch (2020) | Swedish | 🎥✍📋📜 | ||||
| SSL Lexicon | Mesch and Wallin (2012) | Swedish | 🎥📋📜📜 | 20,000 | CC BY-NC-SA 2.5 SE | ||
| VGT Corpus | Van Herreweghe, Mieke and Vermeerbergen, Myriam and Demey, Eline and De Durpel, Hannes and Nyffels, Hilde and Verstraete, Sam (n.d.) | Flemish | 🎥📋 | 140 hours | 120 | CC BY-NC-SA | |
| Video-Based CSL | Huang et al. (2018) | Chinese | 🎥📋👋 | 500 | 25,000 Videos | 50 | Research Attribution |
| WLASL 💾 | Li et al. (2020) | American | 🎥📋 | 2,000 | 100 | C-UDA 1.0 |
Other Resources
- iReviews had compiled a list of Top Resources for Learning (American) Sign Language
Citation
For attribution in academic contexts, please cite this work as:
@misc{moryossef2021slp,
title = "{S}ign {L}anguage {P}rocessing",
author = "Moryossef, Amit and Goldberg, Yoav",
howpublished = "\url{https://sign-language-processing.github.io/}",
year = "2021"
}References
Abeille, Anne, Yves Schabes, and Aravind K. Joshi. 1990. “Using Lexicalized Tags for Machine Translation.” In COLING 1990 Volume 3: Papers Presented to the 13th International Conference on Computational Linguistics. https://aclanthology.org/C90-3001.
Adaloglou, Nikolas, Theocharis Chatzis, Ilias Papastratis, Andreas Stergioulas, Georgios Th Papadopoulos, Vassia Zacharopoulou, George J Xydopoulos, Klimnis Atzakas, Dimitris Papazachariou, and Petros Daras. 2020. “A Comprehensive Study on Sign Language Recognition Methods.” ArXiv Preprint abs/2007.12530. https://arxiv.org/abs/2007.12530.
Adeline, Chloe. 2013. “Fingerspell.net.” http://fingerspell.net/.
Ahuja, Chaitanya, and Louis-Philippe Morency. 2019. “Language2Pose: Natural Language Grounded Pose Forecasting.” In 2019 International Conference on 3D Vision (3DV), 719–28. https://doi.org/10.1109/3DV.2019.00084.
Albanie, Samuel, Gül Varol, Liliane Momeni, Hannah Bull, Triantafyllos Afouras, Himel Chowdhury, Neil Fox, et al. 2021. “BOBSL: BBC-Oxford British Sign Language Dataset.” In. https://www.robots.ox.ac.uk/~vgg/data/bobsl.
Arivazhagan, Naveen, Ankur Bapna, Orhan Firat, Dmitry Lepikhin, Melvin Johnson, Maxim Krikun, Mia Xu Chen, et al. 2019. “Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges.” ArXiv Preprint abs/1907.05019. https://arxiv.org/abs/1907.05019.
Arkushin, Rotem Shalev, Amit Moryossef, and Ohad Fried. 2023. “Ham2Pose: Animating Sign Language Notation into Pose Sequences,” 21046–56.
Athitsos, Vassilis, Carol Neidle, Stan Sclaroff, Joan Nash, Alexandra Stefan, Ashwin Thangali, Haijing Wang, and Quan Yuan. 2010. “Large Lexicon Project: American Sign Language Video Corpus and Sign Language Indexing/Retrieval Algorithms.” In 7th International Conference on Language Resources and Evaluation (LREC 2010), edited by Philippe Dreuw, Eleni Efthimiou, Thomas Hanke, Trevor Johnston, Gregorio Martínez Ruiz, and Adam Schembri, 11–14. Valletta, Malta: European Language Resources Association (ELRA). https://www.sign-lang.uni-hamburg.de/lrec/pub/10022.pdf.
Athitsos, Vassilis, Carol Neidle, Stan Sclaroff, Joan Nash, Alexandra Stefan, Quan Yuan, and Ashwin Thangali. 2008. “The American Sign Language Lexicon Video Dataset.” In 2008 Ieee Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 1–8. IEEE.
authors, TensorFlow. 2019. “TensorFlow Datasets, a Collection of Ready-to-Use Datasets.” GitHub Repository. https://github.com/tensorflow/datasets; GitHub.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2015. “Neural Machine Translation by Jointly Learning to Align and Translate.” In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, ca, Usa, May 7-9, 2015, Conference Track Proceedings, edited by Yoshua Bengio and Yann LeCun. http://arxiv.org/abs/1409.0473.
Bangham, J Andrew, SJ Cox, Ralph Elliott, John RW Glauert, Ian Marshall, Sanja Rankov, and Mark Wells. 2000. “Virtual Signing: Capture, Animation, Storage and Transmission-an Overview of the Visicast Project.” In IEE Seminar on Speech and Language Processing for Disabled and Elderly People (Ref. No. 2000/025), 6–1. IET.
Baowidan, Souad. 2021. “Improving Realism in Automated Fingerspelling of American Sign Language.” Machine Translation 35 (3): 387–404.
Battison, Robbin. 1978. “Lexical Borrowing in American Sign Language.”
Bellugi, Ursula, and Susan Fischer. 1972. “A Comparison of Sign Language and Spoken Language.” Cognition 1 (2-3): 173–200.
Bergman, Brita. 1977. Tecknad Svenska:[Signed Swedish]. LiberLäromedel/Utbildningsförl.:
Berndt, Donald J., and James Clifford. 1994. “Using Dynamic Time Warping to Find Patterns in Time Series.” In KDD Workshop.
Beuzeville, Louise de. 2008. “Pointing and Verb Modification: The Expression of Semantic Roles in the Auslan Corpus.” In Workshop Programme, 13. Citeseer.
Bird, Steven. 2020. “Decolonising Speech and Language Technology.” In Proceedings of the 28th International Conference on Computational Linguistics, 3504–19. Barcelona, Spain (Online): International Committee on Computational Linguistics. https://doi.org/10.18653/v1/2020.coling-main.313.
Bishop, Christopher M. 1994. “Mixture Density Networks.”
Blattmann, Andreas, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 2023. “Align Your Latents: High-Resolution Video Synthesis with Latent Diffusion Models.” In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Borg, Mark, and Kenneth P. Camilleri. 2019. “Sign Language Detection "in the Wild" with Recurrent Neural Networks.” In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, United Kingdom, May 12-17, 2019, 1637–41. IEEE. https://doi.org/10.1109/ICASSP.2019.8683257.
Bragg, Danielle, Oscar Koller, Mary Bellard, Larwan Berke, Patrick Boudreault, Annelies Braffort, Naomi Caselli, et al. 2019. “Sign Language Recognition, Generation, and Translation: An Interdisciplinary Perspective.” In The 21st International Acm Sigaccess Conference on Computers and Accessibility, 16–31.
Brentari, Diane. 2011. “Sign Language Phonology.” The Handbook of Phonological Theory, 691–721.
Brentari, Diane, and Carol Padden. 2001. “A Language with Multiple Origins: Native and Foreign Vocabulary in American Sign Language.” Foreign Vocabulary in Sign Language: A Cross-Linguistic Investigation of Word Formation, 87–119.
Bull, Hannah, Triantafyllos Afouras, Gül Varol, Samuel Albanie, Liliane Momeni, and Andrew Zisserman. 2021. “Aligning Subtitles in Sign Language Videos.” In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, Qc, Canada, October 10-17, 2021, 11532–41. IEEE. https://doi.org/10.1109/ICCV48922.2021.01135.
Bull, Hannah, Michèle Gouiffès, and Annelies Braffort. 2020. “Automatic Segmentation of Sign Language into Subtitle-Units.” In European Conference on Computer Vision, 186–98. Springer.
Camgöz, Necati Cihan, Simon Hadfield, Oscar Koller, and Richard Bowden. 2017. “SubUNets: End-to-End Hand Shape and Continuous Sign Language Recognition.” In IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, 3075–84. IEEE Computer Society. https://doi.org/10.1109/ICCV.2017.332.
Camgöz, Necati Cihan, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden. 2018. “Neural Sign Language Translation.” In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, Ut, Usa, June 18-22, 2018, 7784–93. IEEE Computer Society. https://doi.org/10.1109/CVPR.2018.00812.
Camgöz, Necati Cihan, Ahmet Alp Kındıroğlu, Serpil Karabüklü, Meltem Kelepir, Ayşe Sumru Özsoy, and Lale Akarun. 2016. “BosphorusSign: A Turkish Sign Language Recognition Corpus in Health and Finance Domains.” In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), 1383–8. Portorož, Slovenia: European Language Resources Association (ELRA). https://aclanthology.org/L16-1220.
Camgöz, Necati Cihan, Oscar Koller, Simon Hadfield, and Richard Bowden. 2020a. “Multi-Channel Transformers for Multi-Articulatory Sign Language Translation.” In European Conference on Computer Vision, 301–19.
———. 2020b. “Sign Language Transformers: Joint End-to-End Sign Language Recognition and Translation.” In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, Wa, Usa, June 13-19, 2020, 10020–30. IEEE. https://doi.org/10.1109/CVPR42600.2020.01004.
Camgöz, Necati Cihan, Ben Saunders, Guillaume Rochette, Marco Giovanelli, Giacomo Inches, Robin Nachtrab-Ribback, and Richard Bowden. 2021. “Content4all Open Research Sign Language Translation Datasets.” In 2021 16th Ieee International Conference on Automatic Face and Gesture Recognition (Fg 2021), 1–5. IEEE.
Cao, Zhe, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2017. “Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, Hi, Usa, July 21-26, 2017, 1302–10. IEEE Computer Society. https://doi.org/10.1109/CVPR.2017.143.
Cao, Z., G. Hidalgo Martinez, T. Simon, S. Wei, and Y. A. Sheikh. 2019. “OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields.” IEEE Transactions on Pattern Analysis and Machine Intelligence.
Carreira, Joao, and Andrew Zisserman. 2017. “Quo Vadis, Action Recognition.” ArXiv Preprint abs/1705.07750. https://arxiv.org/abs/1705.07750.
Chai, Xiujuan, Hanjie Wang, and Xilin Chen. 2014. “The Devisign Large Vocabulary of Chinese Sign Language Database and Baseline Evaluations.” Technical Report VIPL-TR-14-SLR-001. Key Lab of Intelligent Information Processing of Chinese Academy of Sciences (CAS), Institute of Computing Technology, CAS.
Chan, Caroline, Shiry Ginosar, Tinghui Zhou, and Alexei A. Efros. 2019. “Everybody Dance Now.” In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, 5932–41. IEEE. https://doi.org/10.1109/ICCV.2019.00603.
Chen, Yu-Hui, Raman Sarokin, Juhyun Lee, Jiuqiang Tang, Chuo-Ling Chang, Andrei Kulik, and Matthias Grundmann. 2023. “Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via Gpu-Aware Optimizations.” In.
Chen, Yu, Chunhua Shen, Xiu-Shen Wei, Lingqiao Liu, and Jian Yang. 2017. “Adversarial Posenet: A Structure-Aware Convolutional Network for Human Pose Estimation.” In IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, 1221–30. IEEE Computer Society. https://doi.org/10.1109/ICCV.2017.137.
Chen, Yutong, Fangyun Wei, Xiao Sun, Zhirong Wu, and Stephen Lin. 2022. “A Simple Multi-Modality Transfer Learning Baseline for Sign Language Translation.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, La, Usa, June 18-24, 2022, 5110–20. IEEE. https://doi.org/10.1109/CVPR52688.2022.00506.
Chen, Yutong, Ronglai Zuo, Fangyun Wei, Yu Wu, Shujie LIU, and Brian Mak. 2022. “Two-Stream Network for Sign Language Recognition and Translation.” In Advances in Neural Information Processing Systems, edited by S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, 35:17043–56. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2022/file/6cd3ac24cdb789beeaa9f7145670fcae-Paper-Conference.pdf.
Cheng, Ka Leong, Zhaoyang Yang, Qifeng Chen, and Yu-Wing Tai. 2020. “Fully Convolutional Networks for Continuous Sign Language Recognition.” In Computer Vision–Eccv 2020: 16th European Conference, Glasgow, Uk, August 23–28, 2020, Proceedings, Part Xxiv 16, 697–714. Springer. https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/4763_ECCV_2020_paper.php.
Cheng, Yiting, Fangyun Wei, Jianmin Bao, Dong Chen, and Wenqiang Zhang. 2023. “CiCo: Domain-Aware Sign Language Retrieval via Cross-Lingual Contrastive Learning.” In 2023 Ieee/Cvf Conference on Computer Vision and Pattern Recognition (Cvpr). https://doi.org/10.1109/CVPR52729.2023.01823.
Cho, Kyunghyun, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. “Learning Phrase Representations Using RNN Encoder–Decoder for Statistical Machine Translation.” In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1724–34. Doha, Qatar: Association for Computational Linguistics. https://doi.org/10.3115/v1/D14-1179.
Contributors, MMPose. 2020. “OpenMMLab Pose Estimation Toolbox and Benchmark.” https://github.com/open-mmlab/mmpose.
Cormier, Kearsy, Sandra Smith, and Zed Sevcikova-Sehyr. 2015. “Rethinking Constructed Action.” Sign Language & Linguistics 18 (2): 167–204.
Coster, Mathieu De, and Joni Dambre. 2023. “Querying a Sign Language Dictionary with Videos Using Dense Vector Search.” In 2023 Ieee International Conference on Acoustics, Speech, and Signal Processing Workshops (Icasspw), 1–5. https://doi.org/10.1109/ICASSPW59220.2023.10193531.
Crasborn, Onno, Richard Bank, Inge Zwitserlood, Els van der Kooij, Anique Schüller, Ellen Ormel, Ellen Nauta, Merel van Zuilen, Frouke van Winsum, and Johan Ros. 2016. “NGT Signbank.” Nijmegen: Radboud University, Centre for Language Studies.
Crasborn, Onno, and Inge Zwitserlood. 2008. “The Corpus NGT: An Online Corpus for Professionals and Laymen.” In.
Cui, Runpeng, Hu Liu, and Changshui Zhang. 2017. “Recurrent Convolutional Neural Networks for Continuous Sign Language Recognition by Staged Optimization.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, Hi, Usa, July 21-26, 2017, 1610–8. IEEE Computer Society. https://doi.org/10.1109/CVPR.2017.175.
———. 2019. “A Deep Neural Framework for Continuous Sign Language Recognition by Iterative Training.” IEEE Transactions on Multimedia 21 (7): 1880–91.
Dafnis, Konstantinos M, Evgenia Chroni, Carol Neidle, and Dimitris N Metaxas. 2022. “Bidirectional Skeleton-Based Isolated Sign Recognition Using Graph Convolution Networks.” In Proceedings of the 13th Conference on Language Resources and Evaluation (Lrec 2022), Marseille, 20-25 June 2022.
Dal Bianco, Pedro, Gastón Rı́os, Franco Ronchetti, Facundo Quiroga, Oscar Stanchi, Waldo Hasperué, and Alejandro Rosete. 2023. “LSA-T: The First Continuous Argentinian Sign Language Dataset for Sign Language Translation.” In Advances in Artificial Intelligence – Iberamia 2022: 17th Ibero-American Conference on Ai, Cartagena de Indias, Colombia, November 23–25, 2022, Proceedings, 293–304. Berlin, Heidelberg: Springer-Verlag. https://doi.org/10.1007/978-3-031-22419-5_25.
Databases, NCSLGR. 2007. “Volumes 2–7.” American Sign Language Linguistic Research Project (Distributed on CD-ROM ….
Davidson, Mary Jo. 2006. “PAULA: A Computer-Based Sign Language Tutor for Hearing Adults.” In Intelligent Tutoring Systems 2006 Workshop on Teaching with Robots, Agents, and Natural Language Processing, 66–72. Citeseer.
De Coster, Mathieu, Dimitar Shterionov, Mieke Van Herreweghe, and Joni Dambre. 2022. “Machine Translation from Signed to Spoken Languages: State of the Art and Challenges.” ArXiv Preprint abs/2202.03086. https://arxiv.org/abs/2202.03086.
Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Fei-Fei Li. 2009. “ImageNet: A Large-Scale Hierarchical Image Database.” In 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA, 248–55. IEEE Computer Society. https://doi.org/10.1109/CVPR.2009.5206848.
De Sisto, Mirella, Dimitar Shterionov, Irene Murtagh, Myriam Vermeerbergen, and Lorraine Leeson. 2021. “Defining Meaningful Units. Challenges in Sign Segmentation and Segment-Meaning Mapping (Short Paper).” In Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (At4ssl), 98–103. Virtual: Association for Machine Translation in the Americas. https://aclanthology.org/2021.mtsummit-at4ssl.11.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–86. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1423.
Dreuw, Philippe, Thomas Deselaers, Daniel Keysers, and Hermann Ney. 2006. “Modeling Image Variability in Appearance-Based Gesture Recognition.” In ECCV Workshop on Statistical Methods in Multi-Image and Video Processing, 7–18.
Dreuw, Philippe, Carol Neidle, Vassilis Athitsos, Stan Sclaroff, and Hermann Ney. 2008. “Benchmark Databases for Video-Based Automatic Sign Language Recognition.” In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08). Marrakech, Morocco: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2008/pdf/287_paper.pdf.
Duarte, Amanda Cardoso, Samuel Albanie, Xavier Giró-i-Nieto, and Gül Varol. 2022. “Sign Language Video Retrieval with Free-Form Textual Queries.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, La, Usa, June 18-24, 2022, 14074–84. IEEE. https://doi.org/10.1109/CVPR52688.2022.01370.
Duarte, Amanda Cardoso, Shruti Palaskar, Lucas Ventura, Deepti Ghadiyaram, Kenneth DeHaan, Florian Metze, Jordi Torres, and Xavier Giró-i-Nieto. 2021. “How2Sign: A Large-Scale Multimodal Dataset for Continuous American Sign Language.” In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, June 19-25, 2021, 2735–44. Computer Vision Foundation / IEEE. https://doi.org/10.1109/CVPR46437.2021.00276.
Dudis, Paul G. 2004. “Body Partitioning and Real-Space Blends.” Cognitive Linguistics 15 (2): 223–38.
Ebling, Sarah, Necati Cihan Camgöz, Penny Boyes Braem, Katja Tissi, Sandra Sidler-Miserez, Stephanie Stoll, Simon Hadfield, et al. 2018. “SMILE Swiss German Sign Language Dataset.” In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: European Language Resources Association (ELRA). https://aclanthology.org/L18-1666.
Efthimiou, Eleni, Stavroula-Evita Fotinea, Thomas Hanke, John Glauert, Richard Bowden, Annelies Braffort, Christophe Collet, Petros Maragos, and François Lefebvre-Albaret. 2012. “Sign Language Technologies and Resources of the Dicta-Sign Project.” In 5th Workshop on the Representation and Processing of Sign Languages: Interactions Between Corpus and Lexicon. Satellite Workshop to the Eighth International Conference on Language Resources and Evaluation (Lrec-2012).
Egea Gómez, Santiago, Euan McGill, and Horacio Saggion. 2021. “Syntax-Aware Transformers for Neural Machine Translation: The Case of Text to Sign Gloss Translation.” In Proceedings of the 14th Workshop on Building and Using Comparable Corpora (Bucc 2021), 18–27. Online (Virtual Mode): INCOMA Ltd. https://aclanthology.org/2021.bucc-1.4.
Elliott, Ralph, John Glauert, Vince Jennings, and Richard Kennaway. 2004. “An Overview of the Sigml Notation and Sigmlsigning Software System.” Sign-Lang LREC 2004, 98–104.
Elliott, Ralph, John RW Glauert, JR Kennaway, and Ian Marshall. 2000. “The Development of Language Processing Support for the Visicast Project.” In Proceedings of the Fourth International Acm Conference on Assistive Technologies, 101–8.
Erard, Michael. 2017. “Why Sign-Language Gloves Don’t Help Deaf People.” The Atlantic 9.
Farag, Iva, and Heike Brock. 2019. “Learning Motion Disfluencies for Automatic Sign Language Segmentation.” In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, United Kingdom, May 12-17, 2019, 7360–4. IEEE. https://doi.org/10.1109/ICASSP.2019.8683523.
Fenlon, Jordan, Kearsy Cormier, and Adam Schembri. 2015. “Building BSL Signbank: The Lemma Dilemma Revisited.” International Journal of Lexicography 28 (2): 169–206.
Fenlon, Jordan, Adam Schembri, and Kearsy Cormier. 2018. “Modification of Indicating Verbs in British Sign Language: A Corpus-Based Study.” Language 94 (1): 84–118.
Ferreira-Brito, Lucinda. 1984. “Similarities & Differences in Two Brazilian Sign Languages.” Sign Language Studies 42: 45–56.
Filhol, Michael, and John McDonald. 2022. “Representation and Synthesis of Geometric Relocations.” In Proceedings of the Lrec2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, 53–58. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.signlang-1.9.
Filhol, Michael, and John C. McDonald. 2020. “The Synthesis of Complex Shape Deployments in Sign Language.” In Proceedings of the Lrec2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, 61–68. Marseille, France: European Language Resources Association (ELRA). https://aclanthology.org/2020.signlang-1.10.
Filhol, Michael, John C McDonald, and Rosalee J Wolfe. 2017. “Synthesizing Sign Language by Connecting Linguistically Structured Descriptions to a Multi-Track Animation System.” In Universal Access in Human–Computer Interaction. Designing Novel Interactions: 11th International Conference, Uahci 2017, Held as Part of Hci International 2017, Vancouver, Bc, Canada, July 9–14, 2017, Proceedings, Part Ii 11, 27–40. Springer.
Forster, Jens, Christoph Schmidt, Oscar Koller, Martin Bellgardt, and Hermann Ney. 2014. “Extensions of the Sign Language Recognition and Translation Corpus RWTH-PHOENIX-Weather.” In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), 1911–6. Reykjavik, Iceland: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2014/pdf/585_Paper.pdf.
Gebre, Binyam Gebrekidan, Peter Wittenburg, and Tom Heskes. 2013. “Automatic Sign Language Identification.” In 2013 Ieee International Conference on Image Processing, 2626–30. IEEE.
Ghosh, Anindita, Noshaba Cheema, Cennet Oguz, Christian Theobalt, and Philipp Slusallek. 2021. “Synthesis of Compositional Animations from Textual Descriptions.” In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, Qc, Canada, October 10-17, 2021, 1376–86. IEEE. https://doi.org/10.1109/ICCV48922.2021.00143.
Giró-i-Nieto, Xavier. 2020. “Can Everybody Sign Now? Exploring Sign Language Video Generation from 2D Poses.” SLRTP 2020: The Sign Language Recognition, Translation & Production Workshop.
Glickman, Neil S, and Wyatte C Hall. 2018. Language Deprivation and Deaf Mental Health. Routledge.
Gong, Jia, Lin Geng Foo, Yixuan He, Hossein Rahmani, and Jun Liu. 2024. “LLMs Are Good Sign Language Translators.” ArXiv Preprint. https://arxiv.org/abs/2404.00925.
Graves, Alex, Santiago Fernández, Faustino J. Gomez, and Jürgen Schmidhuber. 2006. “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks.” In Machine Learning, Proceedings of the Twenty-Third International Conference (ICML 2006), Pittsburgh, Pennsylvania, Usa, June 25-29, 2006, edited by William W. Cohen and Andrew W. Moore, 148:369–76. ACM International Conference Proceeding Series. ACM. https://doi.org/10.1145/1143844.1143891.
Grishchenko, Ivan, and Valentin Bazarevsky. 2020. “MediaPipe Holistic.” https://google.github.io/mediapipe/solutions/holistic.html.
Gutierrez-Sigut, Eva, Brendan Costello, Cristina Baus, and Manuel Carreiras. 2016. “LSE-Sign: A Lexical Database for Spanish Sign Language.” Behavior Research Methods 48 (1): 123–37.
Güler, Riza Alp, Natalia Neverova, and Iasonas Kokkinos. 2018. “DensePose: Dense Human Pose Estimation in the Wild.” In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, Ut, Usa, June 18-22, 2018, 7297–7306. IEEE Computer Society. https://doi.org/10.1109/CVPR.2018.00762.
Hall, Wyatte C, Leonard L Levin, and Melissa L Anderson. 2017. “Language Deprivation Syndrome: A Possible Neurodevelopmental Disorder with Sociocultural Origins.” Social Psychiatry and Psychiatric Epidemiology 52 (6): 761–76.
Hanke, Thomas. 2002. “ILex - a Tool for Sign Language Lexicography and Corpus Analysis.” In Proceedings of the Third International Conference on Language Resources and Evaluation (LREC’02). Las Palmas, Canary Islands - Spain: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2002/pdf/330.pdf.
Hanke, Thomas, Marc Schulder, Reiner Konrad, and Elena Jahn. 2020. “Extending the Public DGS Corpus in Size and Depth.” In Proceedings of the Lrec2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, 75–82. Marseille, France: European Language Resources Association (ELRA). https://aclanthology.org/2020.signlang-1.12.
Harris, Raychelle, Heidi M Holmes, and Donna M Mertens. 2009. “Research Ethics in Sign Language Communities.” Sign Language Studies 9 (2): 104–31.
Hassan, Saad, Larwan Berke, Elahe Vahdani, Longlong Jing, Yingli Tian, and Matt Huenerfauth. 2020. “An Isolated-Signing RGBD Dataset of 100 American Sign Language Signs Produced by Fluent ASL Signers.” In Proceedings of the Lrec2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, 89–94. Marseille, France: European Language Resources Association (ELRA). https://aclanthology.org/2020.signlang-1.14.
Hassan, Saad, Matthew Seita, Larwan Berke, Yingli Tian, Elaine Gale, Sooyeon Lee, and Matt Huenerfauth. 2022. “ASL-Homework-RGBD Dataset: An Annotated Dataset of 45 Fluent and Non-Fluent Signers Performing American Sign Language Homeworks.” In Proceedings of the Lrec2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, 67–72. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.signlang-1.11.
Ho, Jonathan, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey A. Gritsenko, Diederik P. Kingma, et al. 2022. “Imagen Video: High Definition Video Generation with Diffusion Models.” ArXiv Preprint abs/2210.02303. https://arxiv.org/abs/2210.02303.
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long Short-Term Memory.” Neural Computation 9 (8): 1735–80.
Hu, Hezhen, Weichao Zhao, Wengang Zhou, and Houqiang Li. 2023. “SignBERT+: Hand-Model-Aware Self-Supervised Pre-Training for Sign Language Understanding.” IEEE Transactions on Pattern Analysis and Machine Intelligence 45 (9): 11221–39. https://doi.org/10.1109/TPAMI.2023.3269220.
Hu, Hezhen, Weichao Zhao, Wengang Zhou, Yuechen Wang, and Houqiang Li. 2021. “SignBERT: Pre-Training of Hand-Model-Aware Representation for Sign Language Recognition.” In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, Qc, Canada, October 10-17, 2021, 11067–76. IEEE. https://doi.org/10.1109/ICCV48922.2021.01090.
Hu, Hezhen, Wengang Zhou, Junfu Pu, and Houqiang Li. 2021. “Global-Local Enhancement Network for NMF-Aware Sign Language Recognition.” ACM Trans. Multimedia Comput. Commun. Appl. 17 (3). https://doi.org/10.1145/3436754.
Huang, Jie, Wengang Zhou, Houqiang Li, and Weiping Li. 2019. “Attention-Based 3D-CNNs for Large-Vocabulary Sign Language Recognition.” IEEE Transactions on Circuits and Systems for Video Technology 29 (9): 2822–32. https://doi.org/10.1109/TCSVT.2018.2870740.
Huang, Jie, Wengang Zhou, Qilin Zhang, Houqiang Li, and Weiping Li. 2018. “Video-Based Sign Language Recognition Without Temporal Segmentation.” In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (Aaai-18), the 30th Innovative Applications of Artificial Intelligence (Iaai-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (Eaai-18), New Orleans, Louisiana, Usa, February 2-7, 2018, edited by Sheila A. McIlraith and Kilian Q. Weinberger, 2257–64. AAAI Press. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17137.
Huang, Wencan, Wenwen Pan, Zhou Zhao, and Qi Tian. 2021. “Towards Fast and High-Quality Sign Language Production.” In Proceedings of the 29th Acm International Conference on Multimedia, 3172–81.
Huerta-Enochian, Mathew, Du Hui Lee, Hye Jin Myung, Kang Suk Byun, and Jun Woo Lee. 2022. “KoSign Sign Language Translation Project: Introducing the NIASL2021 Dataset.” In Proceedings of the 7th International Workshop on Sign Language Translation and Avatar Technology: The Junction of the Visual and the Textual: Challenges and Perspectives, 59–66. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.sltat-1.9.
Humphries, Tom, Poorna Kushalnagar, Gaurav Mathur, Donna Jo Napoli, Carol Padden, Christian Rathmann, and Scott Smith. 2016. “Avoiding Linguistic Neglect of Deaf Children.” Social Service Review 90 (4): 589–619.
Imashev, Alfarabi, Medet Mukushev, Vadim Kimmelman, and Anara Sandygulova. 2020. “A Dataset for Linguistic Understanding, Visual Evaluation, and Recognition of Sign Languages: The K-RSL.” In Proceedings of the 24th Conference on Computational Natural Language Learning, 631–40. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.conll-1.51.
Isard, Amy. 2020. “Approaches to the Anonymisation of Sign Language Corpora.” In Proceedings of the Lrec2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, 95–100. Marseille, France: European Language Resources Association (ELRA). https://aclanthology.org/2020.signlang-1.15.
Isola, Phillip, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. 2017. “Image-to-Image Translation with Conditional Adversarial Networks.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, Hi, Usa, July 21-26, 2017, 5967–76. IEEE Computer Society. https://doi.org/10.1109/CVPR.2017.632.
Jiang, Songyao, Bin Sun, Lichen Wang, Yue Bai, Kunpeng Li, and Yun Fu. 2021. “Sign Language Recognition via Skeleton-Aware Multi-Model Ensemble.” ArXiv Preprint abs/2110.06161. https://arxiv.org/abs/2110.06161.
Jiang, Zifan, Amit Moryossef, Mathias Müller, and Sarah Ebling. 2023. “Machine Translation Between Spoken Languages and Signed Languages Represented in SignWriting.” In Findings of the Association for Computational Linguistics: EACL 2023, 1706–24. Dubrovnik, Croatia: Association for Computational Linguistics. https://aclanthology.org/2023.findings-eacl.127.
Jiao, Peiqi, Yuecong Min, and Xilin Chen. 2024. “Visual Alignment Pre-Training for Sign Language Translation.” In European Conference on Computer Vision, 349–67. Springer. https://www.ecva.net/papers/eccv_2024/papers_ECCV/html/5894_ECCV_2024_paper.php.
Jiao, Peiqi, Yuecong Min, Yanan Li, Xiaotao Wang, Lei Lei, and Xilin Chen. 2023. “CoSign: Exploring Co-Occurrence Signals in Skeleton-Based Continuous Sign Language Recognition.” In Proceedings of the Ieee/Cvf International Conference on Computer Vision, 20676–86. https://openaccess.thecvf.com/content/ICCV2023/html/Jiao_CoSign_Exploring_Co-occurrence_Signals_in_Skeleton-based_Continuous_Sign_Language_Recognition_ICCV_2023_paper.html.
Johnson, Robert E, and Scott K Liddell. 2011. “Toward a Phonetic Representation of Signs: Sequentiality and Contrast.” Sign Language Studies 11 (2): 241–74.
Johnson, Ronan, Maren Brumm, and Rosalee J Wolfe. 2018. “An Improved Avatar for Automatic Mouth Gesture Recognition.” In Language Resources and Evaluation Conference, 107–8.
Johnston, Trevor. 2008. “From Archive to Corpus: Transcription and Annotation in the Creation of Signed Language Corpora.” In Proceedings of the 22nd Pacific Asia Conference on Language, Information and Computation, 16–29. The University of the Philippines Visayas Cebu College, Cebu City, Philippines: De La Salle University, Manila, Philippines. https://aclanthology.org/Y08-1002.
Johnston, Trevor, and Louise De Beuzeville. 2016. “Auslan Corpus Annotation Guidelines.” Auslan Corpus.
Johnston, Trevor, and Adam Schembri. 2007. Australian Sign Language (Auslan): An Introduction to Sign Language Linguistics. Cambridge University Press.
Joshi, Abhinav, Susmit Agrawal, and Ashutosh Modi. 2023. “ISLTranslate: Dataset for Translating Indian Sign Language.” In Findings of the Association for Computational Linguistics: ACL 2023, 10466–75. Toronto, Canada: Association for Computational Linguistics. https://aclanthology.org/2023.findings-acl.665.
Joze, Hamid Reza Vaezi, and Oscar Koller. 2019. “MS-ASL: A Large-Scale Data Set and Benchmark for Understanding American Sign Language.” In 30th British Machine Vision Conference 2019, BMVC 2019, Cardiff, Uk, September 9-12, 2019, 100. BMVA Press. https://bmvc2019.org/wp-content/uploads/papers/0254-paper.pdf.
Jui, Tonni Das, Gissella Bejarano, and Pablo Rivas. 2022. “A Machine Learning-Based Segmentation Approach for Measuring Similarity Between Sign Languages.” In Proceedings of the Lrec2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, 94–101. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.signlang-1.15.
Kakumasu, Jim. 1968. “Urubu Sign Language.” International Journal of American Linguistics 34 (4): 275–81.
Karras, Tero, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. “Alias-Free Generative Adversarial Networks.” In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Neurips 2021, December 6-14, 2021, Virtual, edited by Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, 852–63. https://proceedings.neurips.cc/paper/2021/hash/076ccd93ad68be51f23707988e934906-Abstract.html.
Karras, Tero, Samuli Laine, and Timo Aila. 2019. “A Style-Based Generator Architecture for Generative Adversarial Networks.” In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, ca, Usa, June 16-20, 2019, 4401–10. Computer Vision Foundation / IEEE. https://doi.org/10.1109/CVPR.2019.00453.
Karras, Tero, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. “Analyzing and Improving the Image Quality of Stylegan.” In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, Wa, Usa, June 13-19, 2020, 8107–16. IEEE. https://doi.org/10.1109/CVPR42600.2020.00813.
Kezar, Lee, Jesse Thomason, and Zed Sehyr. 2023. “Improving Sign Recognition with Phonology.” In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, 2732–7. Dubrovnik, Croatia: Association for Computational Linguistics. https://aclanthology.org/2023.eacl-main.200.
Kim, Jung-Ho, Mathew John Huerta-Enochian, Changyong Ko, and Du Hui Lee. 2024. “SignBLEU: Automatic Evaluation of Multi-Channel Sign Language Translation.” In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (Lrec-Coling 2024), 14796–14811. Torino, Italia: ELRA; ICCL. https://aclanthology.org/2024.lrec-main.1289.
Kimmelman, Vadim. 2014. “Information Structure in Russian Sign Language and Sign Language of the Netherlands.” Sign Language & Linguistics 18 (1): 142–50.
Kingma, Diederik P., Tim Salimans, Ben Poole, and Jonathan Ho. 2021. “Variational Diffusion Models.” ArXiv Preprint abs/2107.00630. https://arxiv.org/abs/2107.00630.
Kipp, Michael. 2001. “Anvil-a Generic Annotation Tool for Multimodal Dialogue.” In Seventh European Conference on Speech Communication and Technology.
Ko, Sang-Ki, Chang Jo Kim, Hyedong Jung, and Choongsang Cho. 2019. “Neural Sign Language Translation Based on Human Keypoint Estimation.” Applied Sciences 9 (13): 2683.
Koller, Oscar, Cihan Camgöz, Hermann Ney, and Richard Bowden. 2019. “Weakly Supervised Learning with Multi-Stream Cnn-Lstm-Hmms to Discover Sequential Parallelism in Sign Language Videos.” IEEE Transactions on Pattern Analysis and Machine Intelligence.
Koller, Oscar, Jens Forster, and Hermann Ney. 2015. “Continuous Sign Language Recognition: Towards Large Vocabulary Statistical Recognition Systems Handling Multiple Signers.” Computer Vision and Image Understanding 141: 108–25. https://doi.org/https://doi.org/10.1016/j.cviu.2015.09.013.
Konrad, Reiner, Thomas Hanke, Gabriele Langer, Dolly Blanck, Julian Bleicken, Ilona Hofmann, Olga Jeziorski, et al. 2020. “MEINE DGS – Annotiert. Öffentliches Korpus Der Deutschen Gebärdensprache, 3. Release / MY DGS – Annotated. Public Corpus of German Sign Language, 3rd Release.” Languageresource. Universität Hamburg. https://doi.org/10.25592/dgs.corpus-3.0.
Konrad, Reiner, Thomas Hanke, Gabriele Langer, Susanne König, Lutz König, Rie Nishio, and Anja Regen. 2018. “Public DGS Corpus: Annotation Conventions.” Project Note AP03-2018-01, DGS-Korpus project, IDGS, Hamburg University.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” In Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a Meeting Held December 3-6, 2012, Lake Tahoe, Nevada, United States, edited by Peter L. Bartlett, Fernando C. N. Pereira, Christopher J. C. Burges, Léon Bottou, and Kilian Q. Weinberger, 1106–14. https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html.
Kusters, Annelies, Maartje De Meulder, and Dai O’Brien. 2017. Innovations in Deaf Studies: The Role of Deaf Scholars. Oxford University Press.
Kusters, Annelies Maria Jozef, Dai O’Brien, and Maartje De Meulder. 2017. “Innovations in Deaf Studies: Critically Mapping the Field.” In Innovations in Deaf Studies, edited by Annelies Kusters, Maartje De Meulder, and Dai O’Brien, 1–53. United Kingdom: Oxford University Press.
Lebert, Marie. 2008. “Project Gutenberg (1971-2008).” Project Gutenberg.
Li, Dongxu, Cristian Rodriguez, Xin Yu, and Hongdong Li. 2020. “Word-Level Deep Sign Language Recognition from Video: A New Large-Scale Dataset and Methods Comparison.” In The Ieee Winter Conference on Applications of Computer Vision, 1459–69.
Liddell, Scott K, and Robert E Johnson. 1989. “American Sign Language: The Phonological Base.” Sign Language Studies 64 (1): 195–277.
Liddell, Scott K, and Melanie Metzger. 1998. “Gesture in Sign Language Discourse.” Journal of Pragmatics 30 (6): 657–97.
Liddell, Scott K, and others. 2003. Grammar, Gesture, and Meaning in American Sign Language. Cambridge University Press.
Liu, Yinhan, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. “Multilingual Denoising Pre-Training for Neural Machine Translation.” Transactions of the Association for Computational Linguistics 8: 726–42. https://doi.org/10.1162/tacl_a_00343.
Lubbers, Mart, and Francisco Torreira. 2013. “Pympi-Ling: A Python Module for Processing ELANs EAF and Praats TextGrid Annotation Files.” https://pypi.python.org/pypi/pympi-ling.
Luong, Thang, Hieu Pham, and Christopher D. Manning. 2015. “Effective Approaches to Attention-Based Neural Machine Translation.” In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 1412–21. Lisbon, Portugal: Association for Computational Linguistics. https://doi.org/10.18653/v1/D15-1166.
Martinez, Gines Hidalgo, Yaadhav Raaj, Haroon Idrees, Donglai Xiang, Hanbyul Joo, Tomas Simon, and Yaser Sheikh. 2019. “Single-Network Whole-Body Pose Estimation.” In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, 6981–90. IEEE. https://doi.org/10.1109/ICCV.2019.00708.
Martínez, Aleix M, Ronnie B Wilbur, Robin Shay, and Avinash C Kak. 2002. “Purdue Rvl-Slll Asl Database for Automatic Recognition of American Sign Language.” In Proceedings. Fourth Ieee International Conference on Multimodal Interfaces, 167–72. IEEE.
Matthes, Silke, Thomas Hanke, Anja Regen, Jakob Storz, Satu Worseck, Eleni Efthimiou, Athanasia-Lida Dimou, Annelies Braffort, John Glauert, and Eva Safar. 2012. “Dicta-Sign–Building a Multilingual Sign Language Corpus.” In Proceedings of the 5th Workshop on the Representation and Processing of Sign Languages: Interactions Between Corpus and Lexicon (Lrec 2012).
McDonald, John C, and Michael Filhol. 2021. “Natural Synthesis of Productive Forms from Structured Descriptions of Sign Language.” Machine Translation 35 (3): 363–86.
McDonald, John C, Rosalee J Wolfe, Sarah Johnson, Souad Baowidan, Robyn Moncrief, and Ningshan Guo. 2017. “An Improved Framework for Layering Linguistic Processes in Sign Language Generation: Why There Should Never Be a ‘Brows’ Tier.” In Universal Access in Human–Computer Interaction. Designing Novel Interactions: 11th International Conference, Uahci 2017, Held as Part of Hci International 2017, Vancouver, Bc, Canada, July 9–14, 2017, Proceedings, Part Ii 11, 41–54. Springer.
McDonald, John C, Rosalee J Wolfe, Jerry C Schnepp, Julie Hochgesang, Diana Gorman Jamrozik, Marie Stumbo, Larwan Berke, Melissa Bialek, and Farah Thomas. 2016. “An Automated Technique for Real-Time Production of Lifelike Animations of American Sign Language.” Universal Access in the Information Society 15: 551–66.
McDonald, John, Ronan Johnson, and Rosalee Wolfe. 2022. “A Novel Approach to Managing Lower Face Complexity in Signing Avatars.” In Proceedings of the 7th International Workshop on Sign Language Translation and Avatar Technology: The Junction of the Visual and the Textual: Challenges and Perspectives, 67–72. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.sltat-1.10.
McKee, David, and Graeme Kennedy. 2000. “Lexical Comparison of Signs from American, Australian, British and New Zealand Sign Languages.” The Signs of Language Revisited: An Anthology to Honor Ursula Bellugi and Edward Klima, 49–76.
Mesch, Johanna, and Lars Wallin. 2012. “From Meaning to Signs and Back: Lexicography and the Swedish Sign Language Corpus.” In Proceedings of the 5th Workshop on the Representation and Processing of Sign Languages: Interactions Between Corpus and Lexicon [Language Resources and Evaluation Conference (Lrec)], 123–26.
———. 2015. “Gloss Annotations in the Swedish Sign Language Corpus.” International Journal of Corpus Linguistics 20 (1): 102–20.
Min, Jianyuan, and Jinxiang Chai. 2012. “Motion Graphs++ a Compact Generative Model for Semantic Motion Analysis and Synthesis.” ACM Transactions on Graphics (TOG) 31 (6): 1–12.
Min, Yuecong, Aiming Hao, Xiujuan Chai, and Xilin Chen. 2021. “Visual Alignment Constraint for Continuous Sign Language Recognition.” In Proceedings of the Ieee/Cvf International Conference on Computer Vision, 11542–51. https://openaccess.thecvf.com/content/ICCV2021/html/Min_Visual_Alignment_Constraint_for_Continuous_Sign_Language_Recognition_ICCV_2021_paper.html.
Momeni, Liliane, Hannah Bull, KR Prajwal, Samuel Albanie, Gül Varol, and Andrew Zisserman. 2022a. “Automatic Dense Annotation of Large-Vocabulary Sign Language Videos.” In Computer Vision–Eccv 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part Xxxv, 671–90. Springer.
Momeni, Liliane, Hannah Bull, K. R. Prajwal, Samuel Albanie, Gül Varol, and Andrew Zisserman. 2022b. “Automatic Dense Annotation of Large-Vocabulary Sign Language Videos.” In Computer Vision – ECCV 2022, edited by Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, 671–90. Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-19833-5_39.
Moncrief, Robyn. 2020. “Extending a Model for Animating Adverbs of Manner in American Sign Language.” In Proceedings of the Lrec2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, 151–56. Marseille, France: European Language Resources Association (ELRA). https://aclanthology.org/2020.signlang-1.25.
———. 2021. “Generalizing a Model for Animating Adverbs of Manner in American Sign Language.” Machine Translation 35 (3): 345–62.
Monteiro, Caio DD, Christy Maria Mathew, Ricardo Gutierrez-Osuna, and Frank Shipman. 2016. “Detecting and Identifying Sign Languages Through Visual Features.” In 2016 Ieee International Symposium on Multimedia (Ism), 287–90. IEEE.
Montemurro, Kathryn, and Diane Brentari. 2018. “Emphatic Fingerspelling as Code-Mixing in American Sign Language.” Proceedings of the Linguistic Society of America 3 (1): 61–61.
Moryossef, Amit, Zifan Jiang, Mathias Müller, Sarah Ebling, and Yoav Goldberg. 2023. “Linguistically Motivated Sign Language Segmentation.” In Findings of the Association for Computational Linguistics: EMNLP 2023, edited by Houda Bouamor, Juan Pino, and Kalika Bali, 12703–24. Singapore: Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-emnlp.846.
Moryossef, Amit, and Mathias Müller. 2021. “Sign Language Datasets.” https://github.com/sign-language-processing/datasets.
Moryossef, Amit, Mathias Müller, Anne Göhring, Zifan Jiang, Yoav Goldberg, and Sarah Ebling. 2023. “An Open-Source Gloss-Based Baseline for Spoken to Signed Language Translation.” In ArXiv Preprint. Vol. abs/2305.17714. https://arxiv.org/abs/2305.17714.
Moryossef, Amit, Ioannis Tsochantaridis, Roee Aharoni, Sarah Ebling, and Srini Narayanan. 2020. “Real-Time Sign-Language Detection Using Human Pose Estimation.” In Computer Vision–Eccv 2020 Workshops: Glasgow, Uk, August 23–28, 2020, Proceedings, Part Ii 16, Slrtp 2020: The Sign Language Recognition, Translation and Production Workshop, 237–48.
Moryossef, Amit, Kayo Yin, Graham Neubig, and Yoav Goldberg. 2021. “Data Augmentation for Sign Language Gloss Translation.” In Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (At4ssl), 1–11. Virtual: Association for Machine Translation in the Americas. https://aclanthology.org/2021.mtsummit-at4ssl.1.
Mukushev, Medet, Aigerim Kydyrbekova, Vadim Kimmelman, and Anara Sandygulova. 2022. “Towards Large Vocabulary Kazakh-Russian Sign Language Dataset: KRSL-OnlineSchool.” In Proceedings of the Lrec2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, 154–58. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.signlang-1.24.
Murray, Joseph J, Wyatte C Hall, and Kristin Snoddon. 2020. “The Importance of Signed Languages for Deaf Children and Their Families.” The Hearing Journal 73 (3): 30–32.
Müller, Mathias, Sarah Ebling, Eleftherios Avramidis, Alessia Battisti, Michèle Berger, Richard Bowden, Annelies Braffort, et al. 2022. “Findings of the First WMT Shared Task on Sign Language Translation (WMT-SLT22).” In Proceedings of the Seventh Conference on Machine Translation (Wmt), 744–72. Abu Dhabi, United Arab Emirates (Hybrid): Association for Computational Linguistics. https://aclanthology.org/2022.wmt-1.71.
Müller, Mathias, Zifan Jiang, Amit Moryossef, Annette Rios, and Sarah Ebling. 2023. “Considerations for Meaningful Sign Language Machine Translation Based on Glosses.” In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 682–93. Toronto, Canada: Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.acl-short.60.
Napier, Jemina, and Lorraine Leeson. 2016. Sign Language in Action. London: Palgrave Macmillan.
Neidle, Carol, and Stan Sclaroff. 2012. “National Center for Sign Language and Gesture Resources (Ncslgr) Corpus. ISLRN 833-505-711-564-4.” Languageresource. Boston University. https://www.islrn.org/resources/833-505-711-564-4/.
Neidle, Carol, Stan Sclaroff, and Vassilis Athitsos. 2001. “SignStream: A Tool for Linguistic and Computer Vision Research on Visual-Gestural Language Data.” Behavior Research Methods, Instruments, & Computers 33 (3): 311–20.
Oliveira, Marlon, Houssem Chatbri, Ylva Ferstl, Mohamed Farouk, Suzanne Little, Noel O’Connor, and A. Sutherland. 2017. “A Dataset for Irish Sign Language Recognition.” In Proceedings of the Irish Machine Vision and Image Processing Conference (IMVIP).
Oord, Aäron van den, Oriol Vinyals, and Koray Kavukcuoglu. 2017. “Neural Discrete Representation Learning.” In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, ca, USA, edited by Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, 6306–15. https://proceedings.neurips.cc/paper/2017/hash/7a98af17e63a0ac09ce2e96d03992fbc-Abstract.html.
Ormel, Ellen, and Onno Crasborn. 2012. “Prosodic Correlates of Sentences in Signed Languages: A Literature Review and Suggestions for New Types of Studies.” Sign Language Studies 12 (2): 279–315.
Othman, Achraf, and Mohamed Jemni. 2012. “English-Asl Gloss Parallel Corpus 2012: Aslg-Pc12.” In 5th Workshop on the Representation and Processing of Sign Languages: Interactions Between Corpus and Lexicon Lrec.
Öqvist, Zrajm, Nikolaus Riemer Kankkonen, and Johanna Mesch. 2020. “STS-Korpus: A Sign Language Web Corpus Tool for Teaching and Public Use.” In Proceedings of the Lrec2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, 177–80. Marseille, France: European Language Resources Association (ELRA). https://aclanthology.org/2020.signlang-1.29.
Özdemir, Oğulcan, Ahmet Alp Kındıroğlu, Necati Cihan Camgöz, and Lale Akarun. 2020. “BosphorusSign22k Sign Language Recognition Dataset.” In Proceedings of the Lrec2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, 181–88. Marseille, France: European Language Resources Association (ELRA). https://aclanthology.org/2020.signlang-1.30.
Padden, C. 1988. Interaction of Morphology and Syntax in American Sign Language. Outstanding Disc Linguistics Series. Garland. https://books.google.com/books?id=Mea7AAAAIAAJ.
Padden, Carol A. 1998. “The ASL Lexicon.” Sign Language & Linguistics 1 (1): 39–60.
Padden, Carol A, and Darline Clark Gunsauls. 2003. “How the Alphabet Came to Be Used in a Sign Language.” Sign Language Studies, 10–33.
Padden, Carol A, and Tom Humphries. 1988. Deaf in America. Harvard University Press.
Pal, Abhilash, Stephan Huber, Cyrine Chaabani, Alessandro Manzotti, and Oscar Koller. 2023. “On the Importance of Signer Overlap for Sign Language Detection.” ArXiv Preprint abs/2303.10782. https://arxiv.org/abs/2303.10782.
Panteleris, Paschalis, Iason Oikonomidis, and Antonis Argyros. 2018. “Using a Single Rgb Frame for Real Time 3d Hand Pose Estimation in the Wild.” In 2018 Ieee Winter Conference on Applications of Computer Vision (Wacv), 436–45. IEEE.
Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. “Bleu: A Method for Automatic Evaluation of Machine Translation.” In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 311–18. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics. https://doi.org/10.3115/1073083.1073135.
Patrie, Carol J, and Robert E Johnson. 2011. Fingerspelled Word Recognition Through Rapid Serial Visual Presentation: RSVP. DawnSignPress.
Pavllo, Dario, Christoph Feichtenhofer, David Grangier, and Michael Auli. 2019. “3D Human Pose Estimation in Video with Temporal Convolutions and Semi-Supervised Training.” In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, ca, Usa, June 16-20, 2019, 7753–62. Computer Vision Foundation / IEEE. https://doi.org/10.1109/CVPR.2019.00794.
Petrovich, Mathis, Michael J. Black, and Gül Varol. 2022. “TEMOS: Generating Diverse Human Motions from Textual Descriptions.” In Computer Vision – ECCV 2022, edited by Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, 480–97. Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-20047-2_28.
Pishchulin, Leonid, Arjun Jain, Mykhaylo Andriluka, Thorsten Thormählen, and Bernt Schiele. 2012. “Articulated People Detection and Pose Estimation: Reshaping the Future.” In 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, Ri, Usa, June 16-21, 2012, 3178–85. IEEE Computer Society. https://doi.org/10.1109/CVPR.2012.6248052.
Pizzuto, Elena Antinoro, Paolo Rossini, and Tommaso Russo. 2006. “Representing Signed Languages in Written Form: Questions That Need to Be Posed.” In 5th International Conference on Language Resources and Evaluation (LREC 2006), edited by Chiara Vettori, 1–6. Genoa, Italy: European Language Resources Association (ELRA). https://www.sign-lang.uni-hamburg.de/lrec/pub/06001.pdf.
Post, Matt. 2018. “A Call for Clarity in Reporting BLEU Scores.” In Proceedings of the Third Conference on Machine Translation: Research Papers, 186–91. Brussels, Belgium: Association for Computational Linguistics. https://doi.org/10.18653/v1/W18-6319.
Pratap, Vineel, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. 2020. “MLS: A Large-Scale Multilingual Dataset for Speech Research.” In Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25-29 October 2020, edited by Helen Meng, Bo Xu, and Thomas Fang Zheng, 2757–61. ISCA. https://doi.org/10.21437/Interspeech.2020-2826.
Prillwitz, Siegmund, Thomas Hanke, Susanne König, Reiner Konrad, Gabriele Langer, and Arvid Schwarz. 2008. “DGS Corpus Project–Development of a Corpus Based Electronic Dictionary German Sign Language/German.” In Sign-Lang at Lrec 2008, 159–64. European Language Resources Association (ELRA).
Prillwitz, Siegmund, and Heiko Zienert. 1990. “Hamburg Notation System for Sign Language: Development of a Sign Writing with Computer Application.” In Current Trends in European Sign Language Research. Proceedings of the 3rd European Congress on Sign Language Research, 355–79.
Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. “Learning Transferable Visual Models from Natural Language Supervision.” In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, edited by Marina Meila and Tong Zhang, 139:8748–63. Proceedings of Machine Learning Research. PMLR. http://proceedings.mlr.press/v139/radford21a.html.
Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” J. Mach. Learn. Res. 21: 140:1–140:67. http://jmlr.org/papers/v21/20-074.html.
Ramırez, Javier, José C Segura, Carmen Benıtez, Angel De La Torre, and Antonio Rubio. 2004. “Efficient Voice Activity Detection Algorithms Using Long-Term Speech Information.” Speech Communication 42 (3-4): 271–87.
Rathmann, Christian, and Gaurav Mathur. 2011. “A Featural Approach to Verb Agreement in Signed Languages.” Theoretical Linguistics 37 (3-4): 197–208.
Renz, Katrin, Nicolaj C Stache, Samuel Albanie, and Gül Varol. 2021a. “Sign Language Segmentation with Temporal Convolutional Networks.” In ICASSP 2021-2021 Ieee International Conference on Acoustics, Speech and Signal Processing (Icassp), 2135–9. IEEE.
Renz, Katrin, Nicolaj C. Stache, Neil Fox, Gül Varol, and Samuel Albanie. 2021b. “Sign Segmentation with Changepoint-Modulated Pseudo-Labelling.” In IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2021, Virtual, June 19-25, 2021, 3403–12. Computer Vision Foundation / IEEE. https://doi.org/10.1109/CVPRW53098.2021.00379.
Rombach, Robin, A. Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2021. “High-Resolution Image Synthesis with Latent Diffusion Models.” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10674–85.
Romero, Javier, Dimitrios Tzionas, and Michael J. Black. 2017. “Embodied Hands: Modeling and Capturing Hands and Bodies Together.” ACM Trans. Graph. 36 (6). https://doi.org/10.1145/3130800.3130883.
Roy, Cynthia B. 2011. Discourse in Signed Languages. Gallaudet University Press.
Rust, Phillip, Bowen Shi, Skyler Wang, Necati Cihan Camgöz, and Jean Maillard. 2024. “Towards Privacy-Aware Sign Language Translation at Scale.” http://arxiv.org/abs/2402.09611.
Ryali, Chaitanya, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, et al. 2023. “Hiera: A Hierarchical Vision Transformer Without the Bells-and-Whistles.” In Proceedings of the 40th International Conference on Machine Learning, edited by Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, 202:29441–54. Proceedings of Machine Learning Research. PMLR. https://proceedings.mlr.press/v202/ryali23a.html.
Sams, Ataher, Ahsan Habib Akash, and S. M. Mahbubur Rahman. 2023. “SignBD-Word: Video-Based Bangla Word-Level Sign Language and Pose Translation.” In 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), 1–7. https://doi.org/10.1109/ICCCNT56998.2023.10306914.
Sandler, Wendy. 2010. “Prosody and Syntax in Sign Languages.” Transactions of the Philological Society 108 (3): 298–328.
———. 2012. “The Phonological Organization of Sign Languages.” Language and Linguistics Compass 6 (3): 162–82.
Sandler, Wendy, and Diane Lillo-Martin. 2006. Sign Language and Linguistic Universals. Cambridge University Press.
Santemiz, Pinar, Oya Aran, Murat Saraclar, and Lale Akarun. 2009. “Automatic Sign Segmentation from Continuous Signing via Multiple Sequence Alignment.” In 2009 Ieee 12th International Conference on Computer Vision Workshops, Iccv Workshops, 2001–8. IEEE.
Saunders, Ben, Richard Bowden, and Necati Cihan Camgöz. 2020. “Adversarial Training for Multi-Channel Sign Language Production.” In 31st British Machine Vision Conference 2020, BMVC 2020, Virtual Event, Uk, September 7-10, 2020. BMVA Press. https://www.bmvc2020-conference.com/assets/papers/0223.pdf.
Saunders, Ben, Necati Cihan Camgöz, and Richard Bowden. 2020a. “Everybody Sign Now: Translating Spoken Language to Photo Realistic Sign Language Video.” ArXiv Preprint abs/2011.09846. https://arxiv.org/abs/2011.09846.
———. 2020b. “Progressive Transformers for End-to-End Sign Language Production.” In European Conference on Computer Vision, 687–705.
———. 2021. “Anonysign: Novel Human Appearance Synthesis for Sign Language Video Anonymisation.” In 2021 16th Ieee International Conference on Automatic Face and Gesture Recognition (Fg 2021), 1–8. https://doi.org/10.1109/FG52635.2021.9666984.
Savitzky, Abraham, and Marcel JE Golay. 1964. “Smoothing and Differentiation of Data by Simplified Least Squares Procedures.” Analytical Chemistry 36 (8): 1627–39.
Schembri, Adam, Kearsy Cormier, and Jordan Fenlon. 2018. “Indicating Verbs as Typologically Unique Constructions: Reconsidering Verb ‘Agreement’in Sign Languages.” Glossa: A Journal of General Linguistics 3 (1).
Schembri, Adam, Jordan Fenlon, Ramas Rentelis, Sally Reynolds, and Kearsy Cormier. 2013. “Building the British Sign Language Corpus.” Language Documentation & Conservation 7: 136–54.
Schnepp, Jerry C, Rosalee J Wolfe, John C McDonald, and Jorge A Toro. 2012. “Combining Emotion and Facial Nonmanual Signals in Synthesized American Sign Language.” In Proceedings of the 14th International Acm Sigaccess Conference on Computers and Accessibility, 249–50.
Schnepp, Jerry C., Rosalee J. Wolfe, John C. McDonald, and Jorge A. Toro. 2013. “Generating Co-Occurring Facial Nonmanual Signals in Synthesized American Sign Language.” In GRAPP/Ivapp.
Sehyr, Zed Sevcikova, Naomi Caselli, Ariel M Cohen-Goldberg, and Karen Emmorey. 2021. “The Asl-Lex 2.0 Project: A Database of Lexical and Phonological Properties for 2,723 Signs in American Sign Language.” The Journal of Deaf Studies and Deaf Education 26 (2): 263–77.
Selvaraj, Prem, Gokul Nc, Pratyush Kumar, and Mitesh Khapra. 2022. “OpenHands: Making Sign Language Recognition Accessible with Pose-Based Pretrained Models Across Languages.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2114–33. Dublin, Ireland: Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.150.
Sennrich, Rico, Barry Haddow, and Alexandra Birch. 2016. “Neural Machine Translation of Rare Words with Subword Units.” In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1715–25. Berlin, Germany: Association for Computational Linguistics. https://doi.org/10.18653/v1/P16-1162.
Shi, Bowen, Diane Brentari, Gregory Shakhnarovich, and Karen Livescu. 2022. “Open-Domain Sign Language Translation Learned from Online Video.” In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 6365–79. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics. https://aclanthology.org/2022.emnlp-main.427.
Shi, Bowen, Aurora Martinez Del Rio, Jonathan Keane, Diane Brentari, Greg Shakhnarovich, and Karen Livescu. 2019. “Fingerspelling Recognition in the Wild with Iterative Visual Attention.” In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, 5399–5408. IEEE. https://doi.org/10.1109/ICCV.2019.00550.
Shi, B., A. Martinez Del Rio, J. Keane, J. Michaux, G. Shakhnarovich D. Brentari, and K. Livescu. 2018. “American Sign Language Fingerspelling Recognition in the Wild.” SLT.
Shieber, Stuart M. 1994. “RESTRICTING the Weak-Generative Capacity of Synchronous Tree-Adjoining Grammars.” Computational Intelligence 10 (4): 371–85.
Shieber, Stuart M., and Yves Schabes. 1990. “Synchronous Tree-Adjoining Grammars.” In COLING 1990 Volume 3: Papers Presented to the 13th International Conference on Computational Linguistics. https://aclanthology.org/C90-3045.
Shroyer, Edgar H, and Susan P Shroyer. 1984. Signs Across America: A Look at Regional Differences in American Sign Language. Gallaudet University Press.
“SiMAX - the Sign Language Avatar SiMAX Project Fact Sheet H2020.” n.d. CORDIS European Commission. Accessed June 18, 2024. https://doi.org/10.3030/778421.
Simon, Tomas, Hanbyul Joo, Iain A. Matthews, and Yaser Sheikh. 2017. “Hand Keypoint Detection in Single Images Using Multiview Bootstrapping.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, Hi, Usa, July 21-26, 2017, 4645–53. IEEE Computer Society. https://doi.org/10.1109/CVPR.2017.494.
Simonyan, Karen, and Andrew Zisserman. 2015. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, ca, Usa, May 7-9, 2015, Conference Track Proceedings, edited by Yoshua Bengio and Yann LeCun. http://arxiv.org/abs/1409.1556.
Sincan, Ozge Mercanoglu, and Hacer Yalim Keles. 2020. “AUTSL: A Large Scale Multi-Modal Turkish Sign Language Dataset and Baseline Methods.” IEEE Access 8: 181340–55.
Sohn, Jongseo, Nam Soo Kim, and Wonyong Sung. 1999. “A Statistical Model-Based Voice Activity Detection.” IEEE Signal Processing Letters 6 (1): 1–3.
Starner, Thad, Sean Forbes, Matthew So, David Martin, Rohit Sridhar, Gururaj Deshpande, Sam Sepah, et al. 2023. “PopSign Asl V1.0: An Isolated American Sign Language Dataset Collected via Smartphones.” In Advances in Neural Information Processing Systems, edited by A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, 36:184–96. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2023/file/00dada608b8db212ea7d9d92b24c68de-Paper-Datasets_and_Benchmarks.pdf.
Stokoe Jr, William C. 1960. “Sign Language Structure: An Outline of the Visual Communication Systems of the American Deaf.” The Journal of Deaf Studies and Deaf Education 10 (1): 3–37. https://doi.org/10.1093/deafed/eni001.
Stoll, Stephanie, Necati Cihan Camgöz, Simon Hadfield, and Richard Bowden. 2018. “Sign Language Production Using Neural Machine Translation and Generative Adversarial Networks.” In British Machine Vision Conference 2018, BMVC 2018, Newcastle, Uk, September 3-6, 2018, 304. BMVA Press. http://bmvc2018.org/contents/papers/0906.pdf.
———. 2020. “Text2Sign: Towards Sign Language Production Using Neural Machine Translation and Generative Adversarial Networks.” International Journal of Computer Vision, 1–18.
Supalla, Ted. 1986. “The Classifier System in American Sign Language.” Noun Classes and Categorization 7: 181–214.
Sutton, Valerie. 1990. Lessons in Sign Writing. SignWriting.
Tavella, Federico, Viktor Schlegel, Marta Romeo, Aphrodite Galata, and Angelo Cangelosi. 2022. “WLASL-LEX: A Dataset for Recognising Phonological Properties in American Sign Language.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 453–63. Dublin, Ireland: Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-short.49.
United Nations. 2022. “International Day of Sign Languages.” https://www.un.org/en/observances/sign-languages-day.
Uthus, Dave, Garrett Tanzer, and Manfred Georg. 2023. “YouTube-Asl: A Large-Scale, Open-Domain American Sign Language-English Parallel Corpus.” In Advances in Neural Information Processing Systems, edited by A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, 36:29029–47. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2023/file/5c61452daca5f0c260e683b317d13a3f-Paper-Datasets_and_Benchmarks.pdf.
Van Herreweghe, Mieke and Vermeerbergen, Myriam and Demey, Eline and De Durpel, Hannes and Nyffels, Hilde and Verstraete, Sam. n.d. “Het Corpus VGT. Een digitaal open access corpus van videos and annotaties van Vlaamse Gebarentaal, ontwikkeld aan de Universiteit Gent ism KU Leuven. <www.corpusvgt.be>.” {http://www.corpusvgt.ugent.be/}.
Varol, Gül, Liliane Momeni, Samuel Albanie, Triantafyllos Afouras, and Andrew Zisserman. 2021. “Read and Attend: Temporal Localisation in Sign Language Videos.” In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, June 19-25, 2021, 16857–66. Computer Vision Foundation / IEEE. https://doi.org/10.1109/CVPR46437.2021.01658.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, ca, USA, edited by Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, 5998–6008. https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html.
Viitaniemi, Ville, Tommi Jantunen, Leena Savolainen, Matti Karppa, and Jorma Laaksonen. 2014. “S-Pot - a Benchmark in Spotting Signs Within Continuous Signing.” In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), 1892–7. Reykjavik, Iceland: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2014/pdf/440_Paper.pdf.
Vintar, Špela, Boštjan Jerko, and Marjetka Kulovec. 2012. “Compiling the Slovene Sign Language Corpus.” In 5th Workshop on the Representation and Processing of Sign Languages: Interactions Between Corpus and Lexicon. Language Resources and Evaluation Conference (Lrec), 5:159–62.
Vogler, Christian, and Siome Goldenstein. 2005. “Analysis of Facial Expressions in American Sign Language.” In Proc, of the 3rd Int. Conf. On Universal Access in Human-Computer Interaction, Springer.
Vogler, Christian, and C. Neidle. 2012. “A New Web Interface to Facilitate Access to Corpora: Development of the ASLLRP Data Access Interface.” In. https://api.semanticscholar.org/CorpusID:58305327.
Von Agris, Ulrich, and Karl-Friedrich Kraiss. 2007. “Towards a Video Corpus for Signer-Independent Continuous Sign Language Recognition.” Gesture in Human-Computer Interaction and Simulation, Lisbon, Portugal, May 11.
Walsh, Harry, Ben Saunders, and Richard Bowden. 2022. “Changing the Representation: Examining Language Representation for Neural Sign Language Production.” In Proceedings of the 7th International Workshop on Sign Language Translation and Avatar Technology: The Junction of the Visual and the Textual: Challenges and Perspectives, 117–24. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.sltat-1.18.
Wang, Ting-Chun, Ming-Yu Liu, Jun-Yan Zhu, Nikolai Yakovenko, Andrew Tao, Jan Kautz, and Bryan Catanzaro. 2018. “Video-to-Video Synthesis.” In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, Neurips 2018, December 3-8, 2018, Montréal, Canada, edited by Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett, 1152–64. https://proceedings.neurips.cc/paper/2018/hash/d86ea612dec96096c5e0fcc8dd42ab6d-Abstract.html.
Wei, Shih-En, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. 2016. “Convolutional Pose Machines.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, Nv, Usa, June 27-30, 2016, 4724–32. IEEE Computer Society. https://doi.org/10.1109/CVPR.2016.511.
Wheatland, Nkenge, Ahsan Abdullah, Michael Neff, Sophie Jörg, and Victor Zordan. 2016. “Analysis in Support of Realistic Timing in Animated Fingerspelling.” In 2016 Ieee Virtual Reality (Vr), 309–10. IEEE.
Wilcox, Sherman. 1992. The Phonetics of Fingerspelling. Vol. 4. John Benjamins Publishing.
Wilcox, Sherman, and Sarah Hafer. 2004. “Rethinking Classifiers. Emmorey, K.(Ed.).(2003). Perspectives on Classifier Constructions in Sign Languages. Mahwah, Nj: Lawrence Erlbaum Associates. 332 Pages. Hardcover.” Oxford University Press.
Wittenburg, Peter, Hennie Brugman, Albert Russel, Alex Klassmann, and Han Sloetjes. 2006. “ELAN: A Professional Framework for Multimodality Research.” In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06). Genoa, Italy: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2006/pdf/153_pdf.pdf.
Wolfe, Rosalee, Peter Cook, John C McDonald, and Jerry C Schnepp. 2011. “Linguistics as Structure in Computer Animation: Toward a More Effective Synthesis of Brow Motion in American Sign Language.” Sign Language & Linguistics 14 (1): 179–99.
Wolfe, Rosalee J, Elena Jahn, Ronan Johnson, and John C McDonald. 2019. “The Case for Avatar Makeup.”
Wolfe, Rosalee, John McDonald, Ronan Johnson, Ben Sturr, Syd Klinghoffer, Anthony Bonzani, Andrew Alexander, and Nicole Barnekow. 2022. “Supporting Mouthing in Signed Languages: New Innovations and a Proposal for Future Corpus Building.” In Proceedings of the 7th International Workshop on Sign Language Translation and Avatar Technology: The Junction of the Visual and the Textual: Challenges and Perspectives, 125–30. Marseille, France: European Language Resources Association. https://aclanthology.org/2022.sltat-1.19.
World Federation of the Deaf. 2022. “World Federation of the Deaf - Our Work.” https://wfdeaf.org/our-work/.
World Health Organization. 2021. “Deafness and Hearing Loss.” https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss.
Xiao, Qinkun, Minying Qin, and Yuting Yin. 2020. “Skeleton-Based Chinese Sign Language Recognition and Generation for Bidirectional Communication Between Deaf and Hearing People.” Neural Networks 125: 41–55.
Xie, Saining, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. 2018. “Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-Offs in Video Classification.” In Computer Vision – Eccv 2018, edited by Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, 318–35. Cham: Springer International Publishing.
Yin, Kayo, Amit Moryossef, Julie Hochgesang, Yoav Goldberg, and Malihe Alikhani. 2021. “Including Signed Languages in Natural Language Processing.” In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 7347–60. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.acl-long.570.
Yin, Kayo, and Jesse Read. 2020. “Better Sign Language Translation with STMC-Transformer.” In Proceedings of the 28th International Conference on Computational Linguistics, 5975–89. Barcelona, Spain (Online): International Committee on Computational Linguistics. https://doi.org/10.18653/v1/2020.coling-main.525.
Yu, Bing, Haoteng Yin, and Zhanxing Zhu. 2018. “Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting.” In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden, edited by Jérôme Lang, 3634–40. ijcai.org. https://doi.org/10.24963/ijcai.2018/505.
Zelinka, Jan, and Jakub Kanis. 2020. “Neural Sign Language Synthesis: Words Are Our Glosses.” In The Ieee Winter Conference on Applications of Computer Vision, 3395–3403.
Zhang, Biao, Mathias Müller, and Rico Sennrich. 2023. “SLTUNET: A Simple Unified Model for Sign Language Translation.” In The Eleventh International Conference on Learning Representations. Kigali, Rwanda. https://openreview.net/forum?id=EBS4C77p_5S.
Zhang, Lvmin, and Maneesh Agrawala. 2023. “Adding Conditional Control to Text-to-Image Diffusion Models.” http://arxiv.org/abs/2302.05543.
Zhang, Shilin, and Bo Zhang. 2010. “Using Revised String Edit Distance to Sign Language Video Retrieval.” In 2010 Second International Conference on Computational Intelligence and Natural Computing, 1:45–49. https://doi.org/10.1109/CINC.2010.5643895.
Zhao, Liwei, Karin Kipper, William Schuler, Christian Vogler, Norman Badler, and Martha Palmer. 2000. “A Machine Translation System from English to American Sign Language.” In Proceedings of the Fourth Conference of the Association for Machine Translation in the Americas: Technical Papers, 54–67. Cuernavaca, Mexico: Springer. https://link.springer.com/chapter/10.1007/3-540-39965-8_6.
Zhao, Rui, Liang Zhang, Biao Fu, Cong Hu, Jinsong Su, and Yidong Chen. 2024. “Conditional Variational Autoencoder for Sign Language Translation with Cross-Modal Alignment.” Proceedings of the AAAI Conference on Artificial Intelligence 38 (17): 19643–51. https://doi.org/10.1609/aaai.v38i17.29937.
Zhao, Weichao, Hezhen Hu, Wengang Zhou, Jiaxin Shi, and Houqiang Li. 2023. “BEST: BERT Pre-Training for Sign Language Recognition with Coupling Tokenization.” Proceedings of the AAAI Conference on Artificial Intelligence 37 (3): 3597–3605. https://doi.org/10.1609/aaai.v37i3.25470.
Zhou, Benjia, Zhigang Chen, Albert Clapés, Jun Wan, Yanyan Liang, Sergio Escalera, Zhen Lei, and Du Zhang. 2023. “Gloss-Free Sign Language Translation: Improving from Visual-Language Pretraining.” In Proceedings of the Ieee/Cvf International Conference on Computer Vision, 20871–81. https://openaccess.thecvf.com/content/CVPR2023/html/Yin_Gloss_Attention_for_Gloss-Free_Sign_Language_Translation_CVPR_2023_paper.html.
Zhou, Hao, Wengang Zhou, Weizhen Qi, Junfu Pu, and Houqiang Li. 2021. “Improving Sign Language Translation with Monolingual Data by Sign Back-Translation.” In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, June 19-25, 2021, 1316–25. Computer Vision Foundation / IEEE. https://doi.org/10.1109/CVPR46437.2021.00137.
Zwitserlood, Inge, Margriet Verlinden, Johan Ros, Sanny Van Der Schoot, and T Netherlands. 2004. “Synthetic Signing for the Deaf: Esign.” In Proceedings of the Conference and Workshop on Assistive Technologies for Vision and Hearing Impairment, Cvhi.
Łacheta, Joanna, and PawełRutkowski. 2014. “A Corpus-Based Dictionary of Polish Sign Language (Pjm).” In.
When capitalized, “Deaf” refers to a community of deaf people who share a language and a culture, whereas the lowercase “deaf” refers to the audiological condition of not hearing. We follow the more recent convention of abandoning a distinction between “Deaf” and “deaf”, using the latter term also to refer to (deaf) members of the sign language community (Napier and Leeson 2016; Annelies Maria Jozef Kusters, O’Brien, and De Meulder 2017).↩︎
We mainly refer to ASL, where most sign language research has been conducted, but not exclusively.↩︎